
今天再来聊聊Power Automate Desktop的使用,之前我们介绍过如何利用“浏览器自动化和UI自动化”,获取某个时间段内关于某个关键词的热门youtube视频,然后让chatgpt帮我总结youtube视频,并用剪映自动生成一个新的视频,最后把内容用telegram bot发送给我这样一个场景。(详见微软Power Automate Desktop 之“UI自动化、浏览器自动化”)
发现自动化RPA还是蛮有意思的,可以很方便的实现一些重复工作,尤其对于不懂代码的朋友,可以很容易的配置出一个工作流。
*Power Automate Desktop官网下载地址:https://learn.microsoft.com/en-us/power-automate/desktop-flows/install#install-power-automate-using-the-msi-installer
今天再说说Power Automate Desktop的“条件、循环和计数器”的功能。我们照旧还是找个实际需求来介绍,直接讲功能可能会比较抽象。
大概需求是这样:我想获取关于IT信息的最新最热新闻,获取5条就行,然后把这5条新闻的标题和链接用telegram bot发送给我。
我就选择hacker news这个新闻网站吧,链接和api地址在下面。
我们看它的API描述发现,它提供的API,可以获取500条最新的新闻ID。

那我们实现需求大概的思路是这样:
step1:通过API获取500条新闻的ID。
step2:取前5条新闻的ID,然后循环这5条新闻,分别获取到这5条新闻的标题和链接。
step3:把这5条新闻的标题和链接用telegram bot发送给我。
接下来我们分步骤说明:
1、获取500条新闻的ID
我们用“调用web服务”的节点功能,把api的url复制进去(url在接口文档里有),然后选择get方法,内容类型为json。点保存即可。
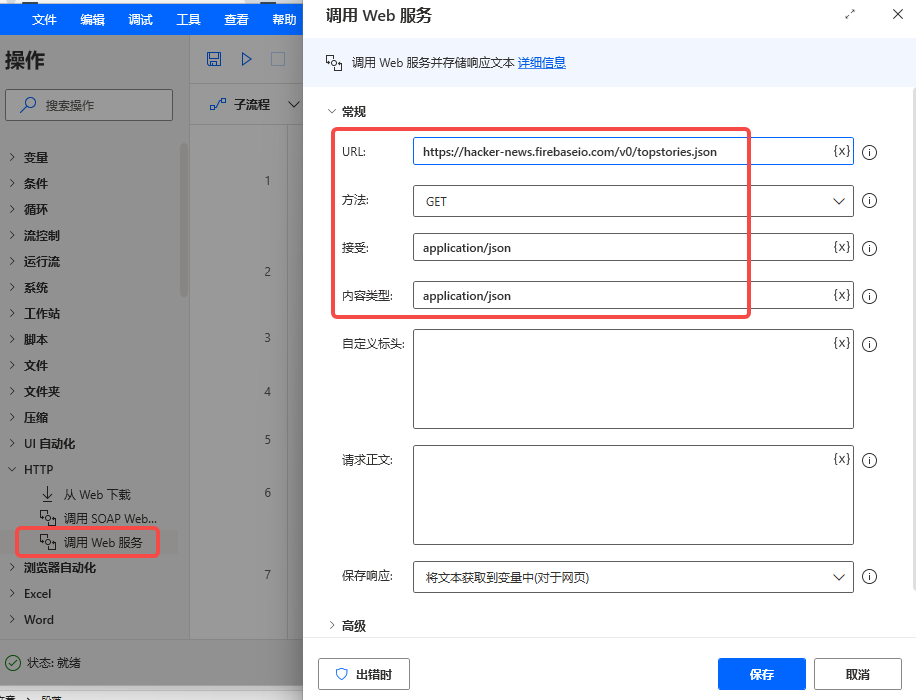
把弹框往下拖动,你会发现调用web服务后,会生成三个变量。

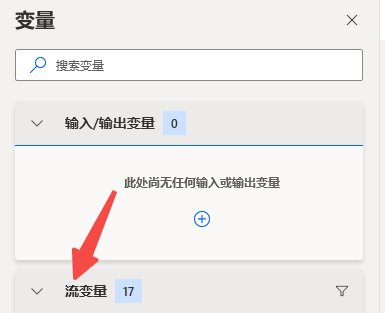
你可以先运行这个节点试试看。在右侧的“流变量”这里,可以看到输出的结果。
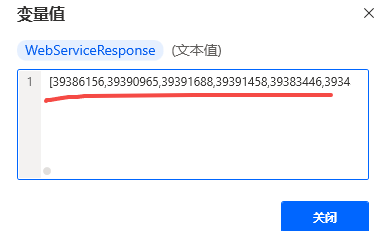
statuscode是状态码,200说明是成功了,然后我们看webserviceresponse,看到已经成功的把前500个id返回给我们了。
2、将json转为自定义对象
第一步最后我们获取到的webserviceresponse变量值是一串json文本,我们需要转变一下格式,转变为对象,这样在后面我们比较好获取到前5个id并分别根据id获取新闻标题和链接。如果不太理解可以看后面步骤的内容,整体来看可能会比较好理解一些。
继续拖动一个“将json转为自定义对象”的节点,选择第一步的变量webserviceresponse,保存即可,这时你可以再运行下试试看。
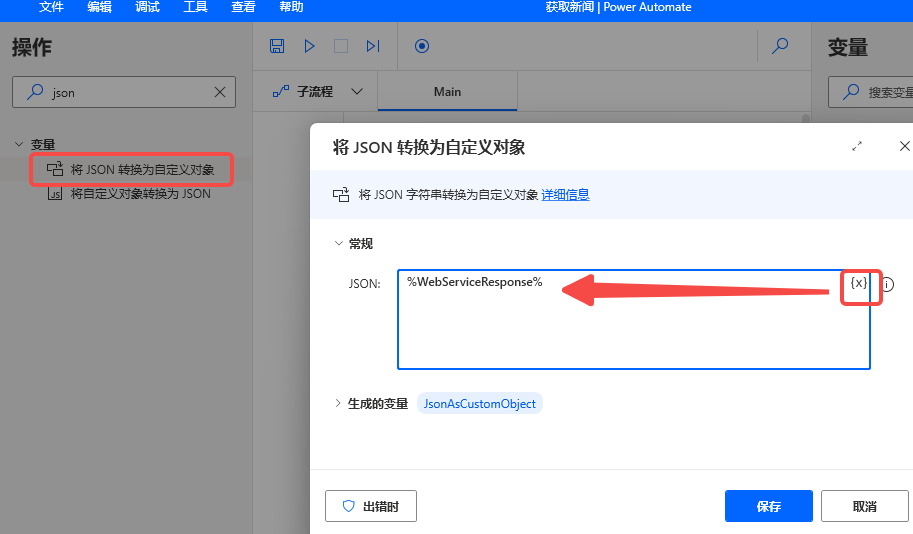
如下,会发现格式已经转变成了列表数值的样式,每个id,都是一个对象。
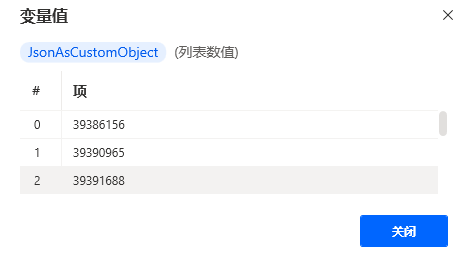
3、取前5条新闻的ID,然后循环这5条新闻,分别获取到这5条新闻的标题和链接
这一步的逻辑相对复杂一点,要用到循环、条件和计数器的概念。
大概的思路是这样,我们已经有了500个id值了。然后呢,我就从第一个id开始,根据id获取新闻的标题和链接,第一个id获取完成,再获取第二个id….以此类推,一直到第五个id,获取完成后,流程结束。
如何配置呢?我直接把这一块的整体贴出来,看起来可能直观一些。
我们先看计数器,因为没有这个功能,我们用变量的方式实现。
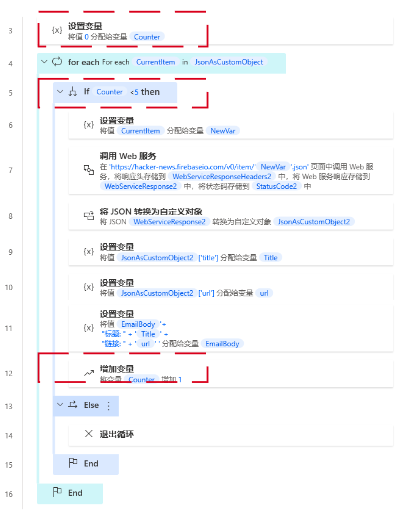
如上红框处:我们先设置一个变量,给它分配一个值“0”。然后,我们循环id,每循环一次,变量值就+1,当等于5的时候,这个循环就结束了。目的就是只取前5个id。这里就用到了计数器,以及if-else循环。
然后,我们就根据获取到的5个id,分别去取这5个id的新闻标题和链接。如下红框处。
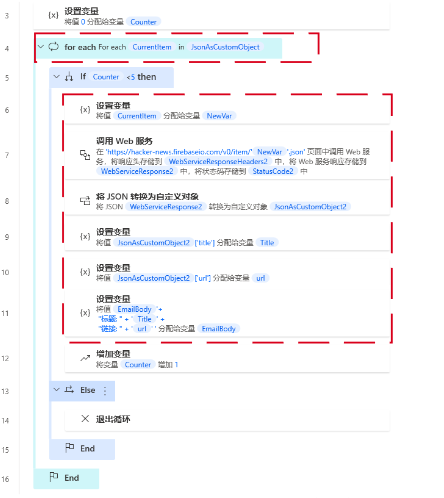
这里我们用到for each循环。
说下这里的要点
我们把循环出来的id存在变量里,比如newvar。
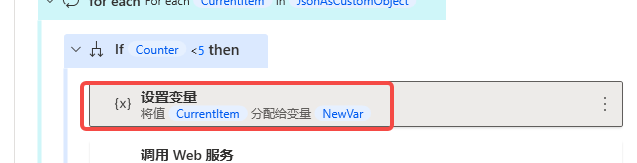
然后我们通过api获取web内容
如下,url其他内容是固定的,id这里是动态的,我们选择上一步的newvar变量。
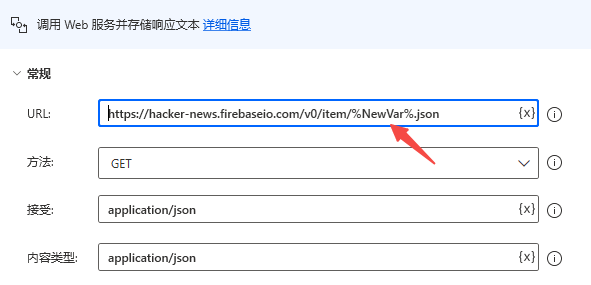
获取到的web内容是json的格式,同理,我们把它转成自定义对象,然后分别设置title和url变量,也就是新闻标题和链接,如下:

title和url的变量值要写对:%JsonAsCustomObject2[‘title’]%、%JsonAsCustomObject2[‘url’]%
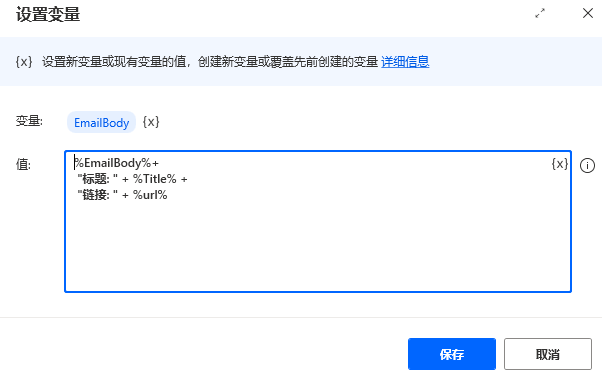
最后一步我们设置一个变量,也就是把这5条新闻的标题、链接合并起来,设置成一个变量。

4、把这5条新闻的标题和链接用telegram bot发送给我

最后我们再配置一个http节点,给telegram bot发送消息,url里拼接好bot的token,chatid和发送的text变量,这个节点之前有讲过,这里就不详细说了。
到此,我们的配置就完成了。
以上就是用Power Automate Desktop来实现获取新闻的自动化流程,挺有意思的吧?
说完了用Power Automate Desktop实现无代码配置,最后我们也可以试试用python来完成这个逻辑(适合初学者,经验丰富者就可以跳过了)
首先我们执行API调用,打印响应的状态
import requests
url = 'https://hacker-news.firebaseio.com/v0/topstories.json'
r = requests.get(url)
print("Status code:",r.status_code)然后呢这个api调用,会返回一个列表,这个列表就是500个新闻的id,我们将响应文本转换为一个Python列表。并将其存储在submission_ids中。我们将使用这些ID来创建一系列字典,其中每个字典都存储了一篇文章的信息。
submission_ids = r.json() 然后我们创建了一个名为submission_dicts的空列表,用于存储前面所说的字典
submission_dicts = [] 接下来,我们遍历前5篇文章的ID,对于每篇文章,都执行一个API调用,URL里面就包含submission_id的当前值。我们为当前处理的文章创建一个字典,并在其中存储文章的标题以及到其讨论页面的链接,然后我们遍历列表,对于每篇热门文章,都打印其标题、链接。最后,我们将submission_dict附加到submission_dicts末尾。
for submission_id in submission_ids[:5]:
url = ('https://hacker-news.firebaseio.com/v0/item/'+
str(submission_id)+'.json')
submission_r = requests.get(url)
print(submission_r.status_code)
response_dict = submission_r.json()
submission_dict = {
'title':response_dict['title'],
'link':'http://news.ycombinator.com/item?id='+str(submission_id),
}
submission_dicts.append(submission_dict)最后我们就通过telegram bot把新闻的标题和链接发送出来。
def send_telegram_message(bot_token, chat_id, message):
send_text = 'https://api.telegram.org/bot' + bot_token + '/sendMessage?chat_id=' + chat_id + '&parse_mode=Markdown&text=' + message
response = requests.get(send_text)
return response.json()
bot_token = 'your_bot_token'
chat_id = 'your_chat_id'
for submission_dict in submission_dicts:
title = submission_dict['title']
link = submission_dict['link']
message = f"Title: {title}\nLink: {link}"
send_telegram_message(bot_token, chat_id, message)这样就ok了。
视频介绍:

评论区已关闭。