
之前有介绍过一个自动化工作流:Get top5 on Product Hunt。也就是说每天定时通过邮件给你发送Product Hunt上的top5产品信息,帮你快速了解最新产品动态。(这一篇文章在这里:Get top5 on Product Hunt | n8n自动化工作流)
Product Hunt网站:https://www.producthunt.com/
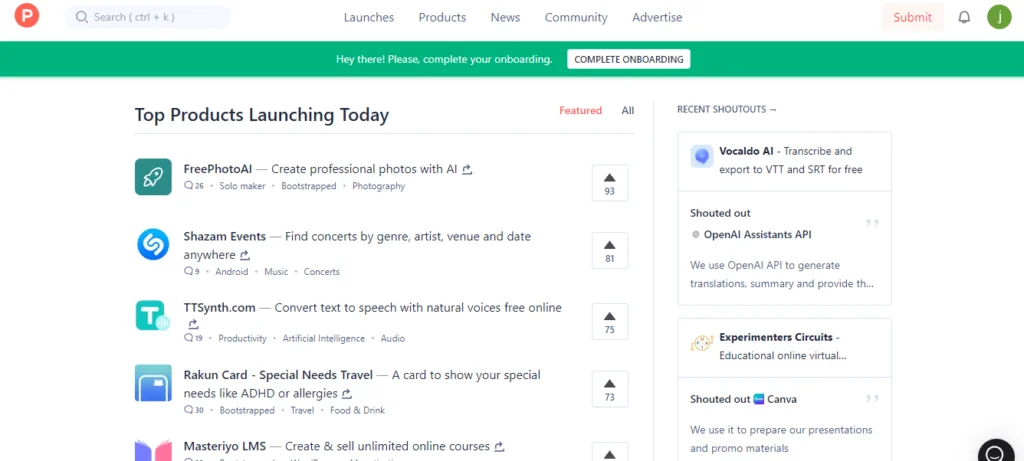
每天收到的邮件信息:
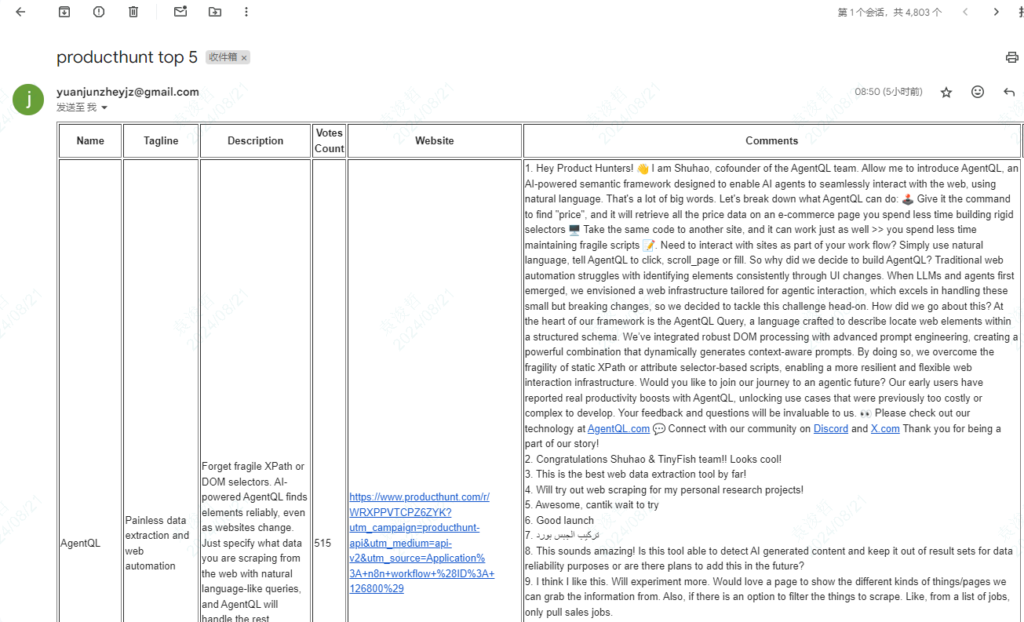
那么问题来了,针对产品的大篇幅的评论,看起来比较耗时,我能否用AI模型,来整理评论的重要信息?比如是正面还是负面评价,评论里是否有用户的需求,是否有用户提出了产品建议之类的。 这样帮你了解产品趋势和用户想法也是非常有价值的。
比如在之前的表格下面,加一行AI的总结。

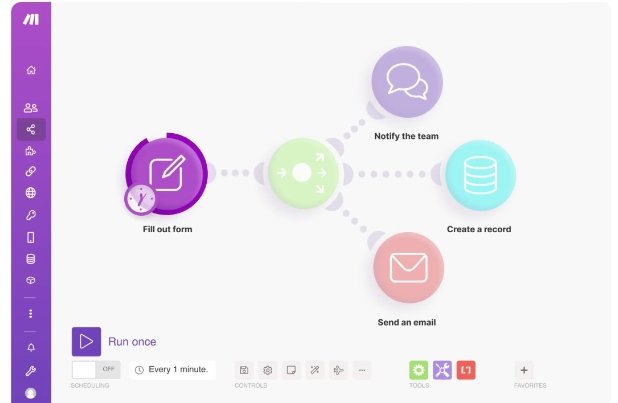
这就需要我们在n8n的流程上增加AI的节点,今天我们就来介绍下,如何在n8n使用AI节点,来达到我们分析评论的需求。
我们先说一下这个AI节点要如何配置。
其实n8n里也内置了不少AI的模型。
我们在新建节点里点击Advanced AI,就可以进行选择了。
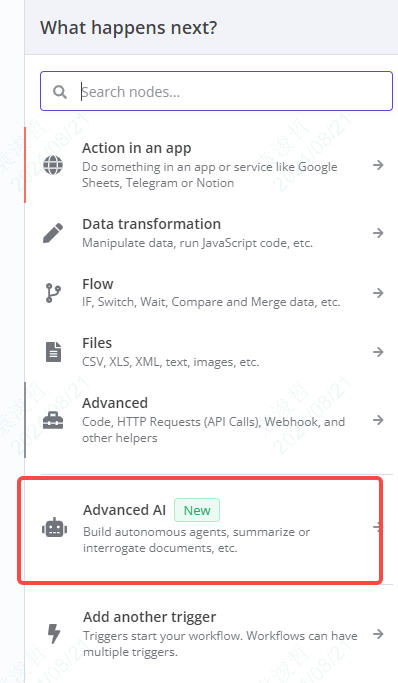

选择后,通过API key连接上你的AI模型即可。

不过我们今天不通过这种方法来用AI模型(主要是这些模型我都没有充值渠道,没法用 o(╥﹏╥)o )
我们直接用HTTP Request节点的方式来连接AI模型
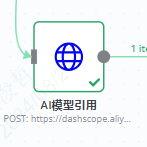
这里我选择用阿里的通义千问AI模型来试试。因为通义千问的qwen-turbo模型,注册后的一个月内,提供了免费的1000000个token使用。还是很方便的。
官网:https://dashscope.console.aliyun.com/
在官网注册完成之后,创建一个API key,复制后妥善保管。

接下来我们通过API来使用通义千问。
可以参考API文档里的参数说明。
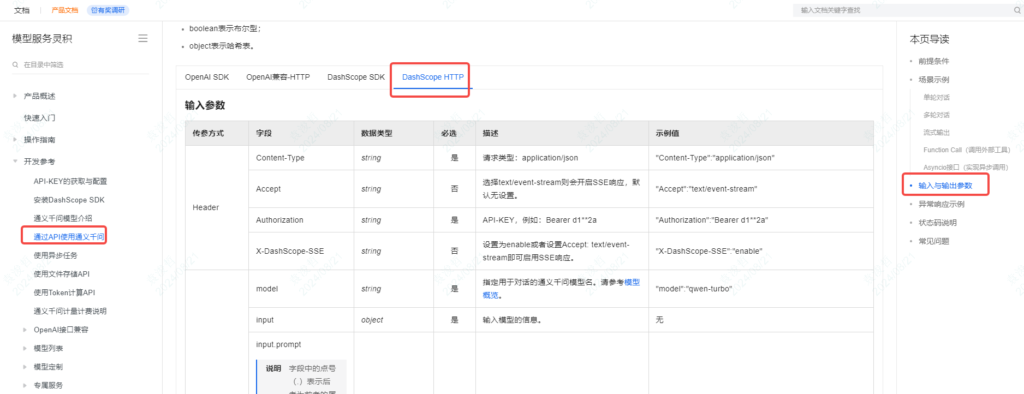
好的,那么我们在n8n的HTTP Request节点来配置

这几个配置项如下:
1、method:POST
2、URL:https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation 这个是AI模型的API地址
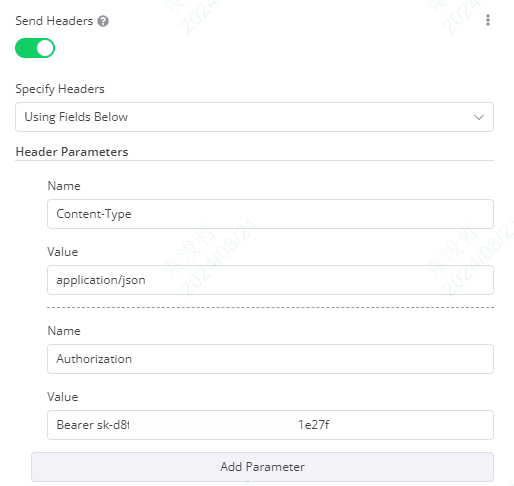
3、headers:把header的开关打开,需要配置两个参数
①name:Content-Type ;value:application/json
②name:Authorization ;value:Bearer [your api key]
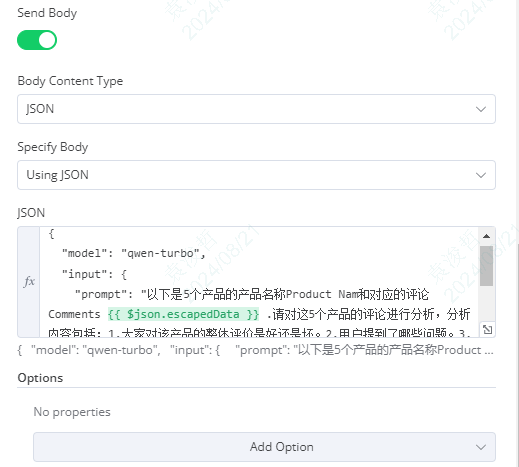
4、body:把body的开关打开,body的类型选择json,然后在json的输入框内输入模型的信息。
这里需要两个字段:
model:数据类型是string,指定用于对话的通义千问模型名,如qwen-turbo
input:数据类型为object,输入模型的信息,这里重要是要输入prompt
大概得一个结构是这样的:
{
"model": "qwen-turbo",
"input": {
"prompt": "请输入你的prompt"
}
} 比如我先这样定义了我的prompt
{
"model": "qwen-turbo",
"input": {
"prompt": "以下是5个产品的产品名称Product Nam和对应的评论Comments {{ $json.escapedData }} .请对这5个产品的评论进行分析,分析内容包括:1.大家对该产品的整体评价是好还是坏。2.用户提到了哪些问题。3.用户提到了哪些需求或改进建议。4.请为每个产品给出一个总结性的结论。请用中文输出,并保持结构清晰."
}
} 注:{{ $json.escapedData }}是一个变量,数据是从前面节点中output出来的。 这里注意一定要是字符串的格式,不然整个json格式会有问题并且报错。
执行后大概是这样的一个效果:
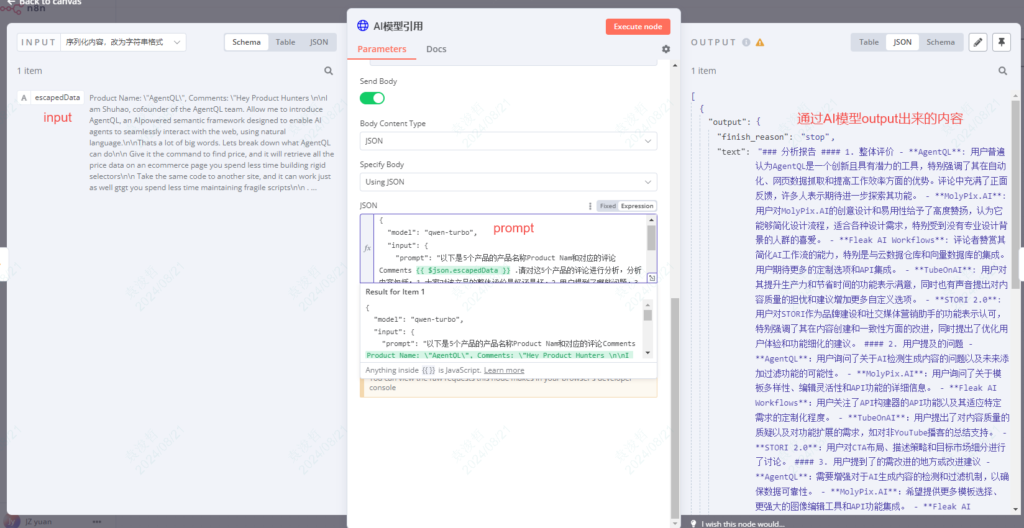
这就是AI模型节点的一个配置方法。
然后我们看下其他节点的配置。
首先是prompt里的{{ $json.escapedData }},因为是字符串格式,所以从一开始的GraphQL接口输出的数据,就要在过程中进行一些加工。
接下来分别来讲讲(我这几个节点稍微麻烦了一点,主要过程中的各种调试加多了几个code节点,其实可以再简洁一点,不过没关系,我先按这样来说明逻辑,有时间可以做一些简洁和优化)
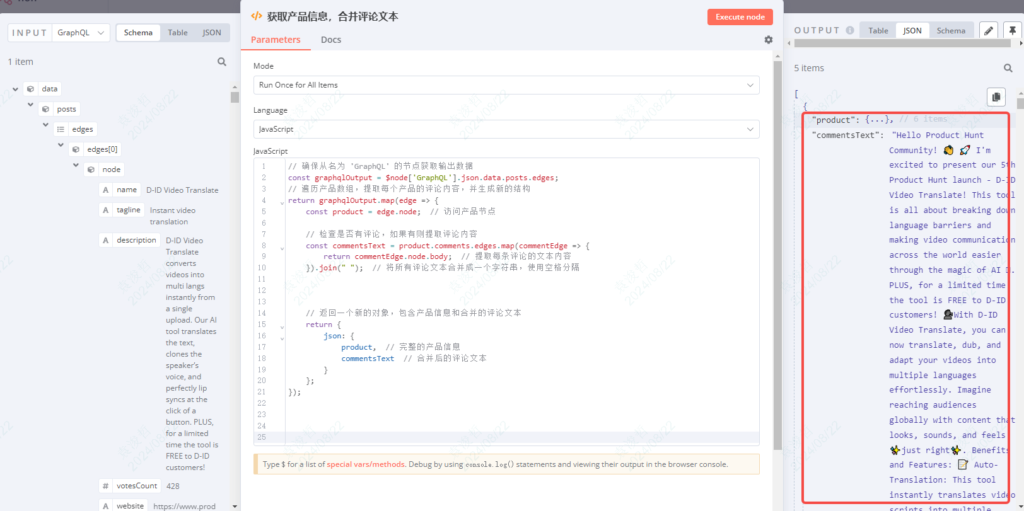
1、获取产品信息,合并评论文本
这一步主要是想把每个产品中的评论都合并在一起,为了后面统一丢给AI去分析。
因为GraphQL接口输出的数据,评论字段是如下的结构,每个评论都在一个node对象里。
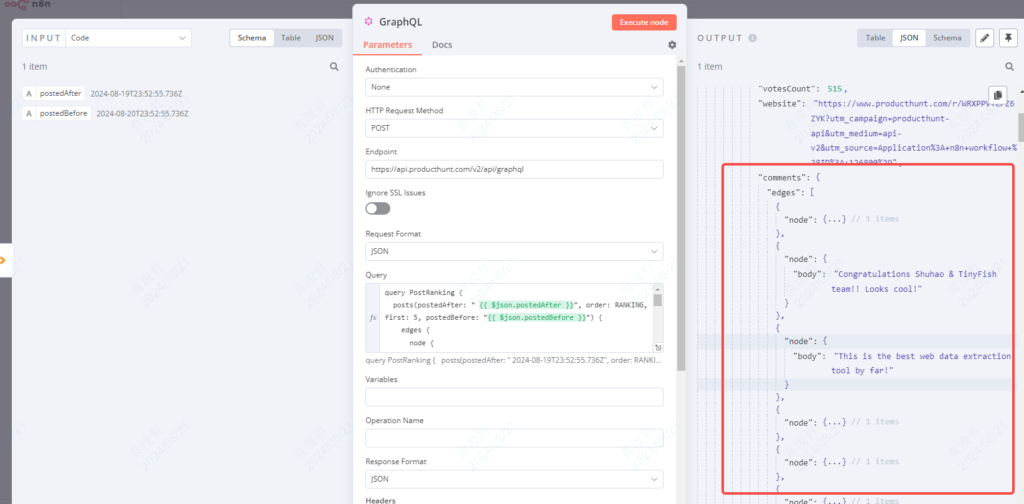
所以这一步主要想把每个产品里的node的数据都分别合并起来
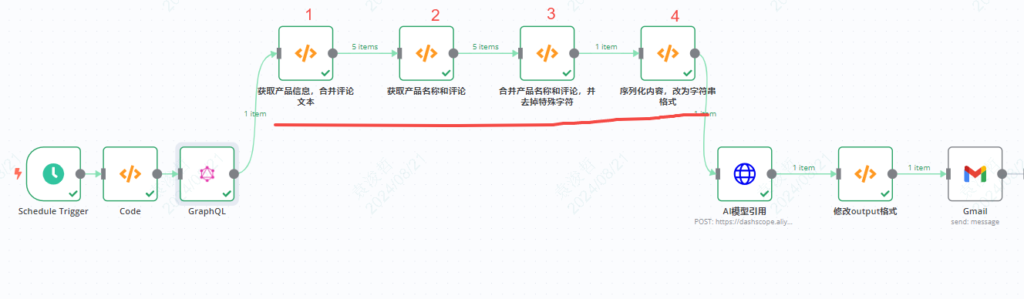
// 确保从名为 'GraphQL' 的节点获取输出数据
const graphqlOutput = $node['GraphQL'].json.data.posts.edges;
// 遍历产品数组,提取每个产品的评论内容,并生成新的结构
return graphqlOutput.map(edge => {
const product = edge.node; // 访问产品节点
// 检查是否有评论,如果有则提取评论内容
const commentsText = product.comments.edges.map(commentEdge => {
return commentEdge.node.body; // 提取每条评论的文本内容
}).join(" "); // 将所有评论文本合并成一个字符串,使用空格分隔
// 返回一个新的对象,包含产品信息和合并的评论文本
return {
json: {
product, // 完整的产品信息
commentsText // 合并后的评论文本
}
};
});2、获取产品名称和评论
把产品名称和合并后的评论分别都提取出来。
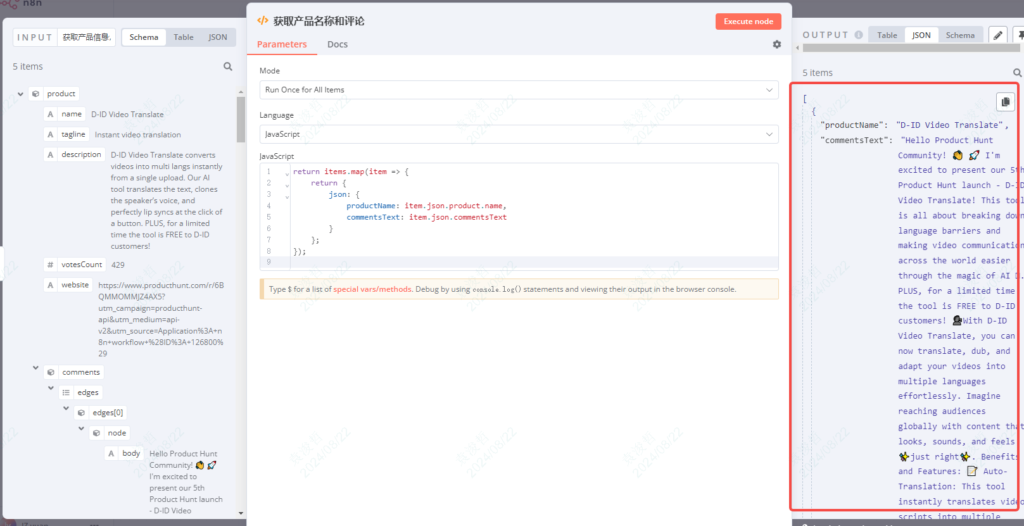
return items.map(item => {
return {
json: {
productName: item.json.product.name,
commentsText: item.json.commentsText
}
};
});3、合并产品名称和评论,并去掉特殊字符
这一步把产品名称和评论合并在一起,并且把里面的特殊表情字符都去掉。
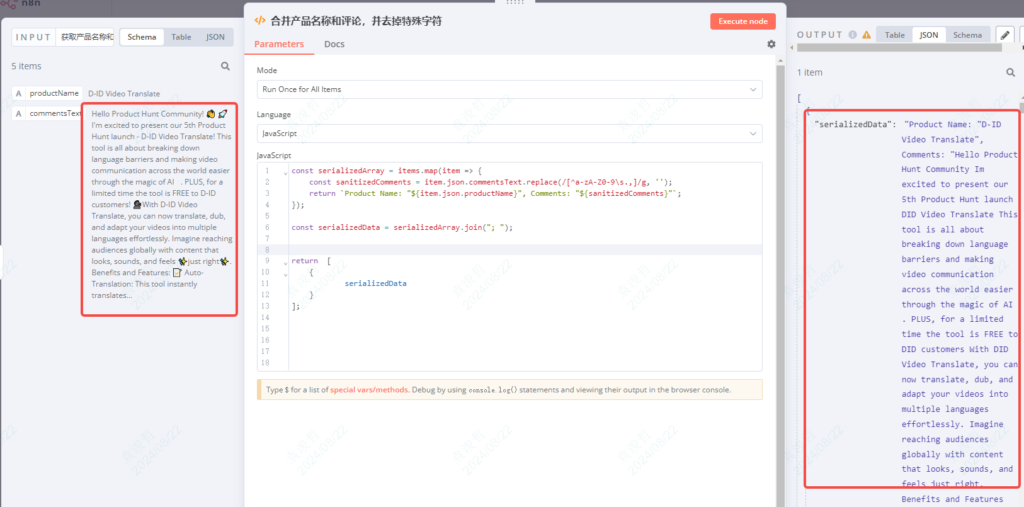
const serializedArray = items.map(item => {
const sanitizedComments = item.json.commentsText.replace(/[^a-zA-Z0-9\s.,]/g, '');
return `Product Name: "${item.json.productName}", Comments: "${sanitizedComments}"`;
});
const serializedData = serializedArray.join("; ");
return [
{
serializedData
}
];4、序列化内容,改为字符串格式
最后是需要把数据的格式改一下,变成字符串,后面给到AI模型节点,在prompt里面就不会出错。
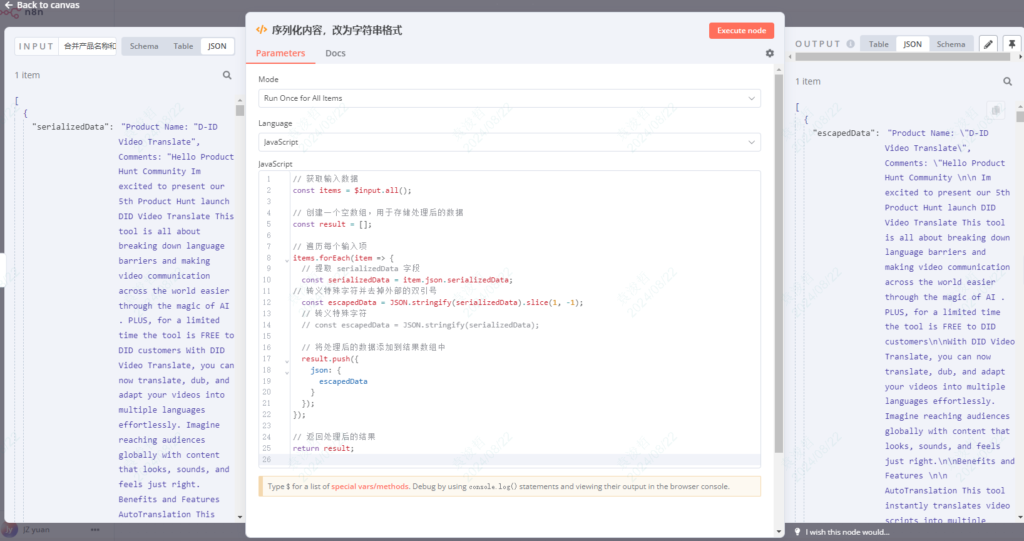
// 获取输入数据
const items = $input.all();
// 创建一个空数组,用于存储处理后的数据
const result = [];
// 遍历每个输入项
items.forEach(item => {
// 提取 serializedData 字段
const serializedData = item.json.serializedData;
// 转义特殊字符并去掉外部的双引号
const escapedData = JSON.stringify(serializedData).slice(1, -1);
// 将处理后的数据添加到结果数组中
result.push({
json: {
escapedData
}
});
});
// 返回处理后的结果
return result;好了,这些处理完了,就回到我们一开始介绍的http节点来实现AI模型的调用。
调用完成后,我们用code节点把内容变成表格的样式,然后通过gmail发送即可。
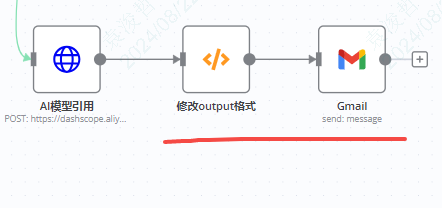
修改output格式节点
return items.map(item => {
const product = $node['GraphQL'].json.data.posts.edges.map(edge => edge.node);
// 获取上一个 n8n 节点输出的文本内容
let textContent = $node['AI模型引用'].json.output.text;
// 做一些换行的操作,让文本看着更清晰一点
textContent = textContent
.replace(/#### /g, '<br>#### ')
.replace(/- \*\*/g, '<br>- **');
const tableRows = product.map(prod => {
const comments = prod.comments.edges.map((comment, index) => `${index + 1}. ${comment.node.body}`).join("<br>");
return `<tr>
<td>${prod.name}</td>
<td>${prod.tagline}</td>
<td>${prod.description}</td>
<td>${prod.votesCount}</td>
<td><a href="${prod.website}">${prod.website}</a></td>
<td>${comments}</td>
</tr>`;
}).join("");
// 在表格末尾追加一个合并的text列
const tableHTML = `
<table border="1">
<thead>
<tr>
<th>Name</th>
<th>Tagline</th>
<th>Description</th>
<th>Votes Count</th>
<th>Website</th>
<th>Comments</th>
</tr>
</thead>
<tbody>
${tableRows}
<tr>
<td colspan="6">${textContent}</td> <!-- 合并所有单元格的text列 -->
</tr>
</tbody>
</table>
`;
return {
json: {
tableHTML: tableHTML
}
};
});gmail节点的配置方法我这里就不详细说了,之前这一篇文章有介绍,需要的话可以看这里:Get top5 on Product Hunt | n8n自动化工作流)
那么到此,这个流程就配置完成了。
最后还是提醒一句,记得保存并且把运行开关打开。这样流程才会开始自动化运行。
купить аккаунт перепродажа аккаунтов
купить аккаунт продажа аккаунтов соцсетей
заработок на аккаунтах маркетплейс аккаунтов
купить аккаунт маркетплейс аккаунтов
гарантия при продаже аккаунтов маркетплейс для реселлеров
Website for Buying Accounts Accounts marketplace
Account Trading https://accountsmarketplacepro.com/
Account Store Buy Account
Account Market Purchase Ready-Made Accounts
Guaranteed Accounts Account Selling Service
Account Exchange Service socialaccountsstore.com
Accounts market Sell Pre-made Account
Account Selling Service Account Acquisition
Sell Pre-made Account Accounts for Sale
Account Buying Platform Account market
Account Trading Platform Buy Pre-made Account
marketplace for ready-made accounts gaming account marketplace
accounts for sale secure account sales
accounts for sale guaranteed accounts
account trading secure account purchasing platform
ready-made accounts for sale account trading
account trading platform buy pre-made account
account market account trading platform
buy and sell accounts buy accounts
social media account marketplace ready-made accounts for sale
website for buying accounts account trading service
ready-made accounts for sale account trading platform
account trading platform account market
account trading platform account market
buy and sell accounts gaming account marketplace
accounts marketplace sell account
account market buy pre-made account
purchase ready-made accounts profitable account sales
website for selling accounts guaranteed accounts
account selling service account sale
website for selling accounts account selling service
account trading sell accounts
account acquisition account trading service
ready-made accounts for sale accounts for sale
secure account purchasing platform buy accounts
account buying platform account selling platform
sell account shop-social-accounts.org
guaranteed accounts guaranteed accounts
account trading platform accounts for sale
account selling platform https://accounts-offer.org/
buy account https://accounts-marketplace.xyz/
sell pre-made account https://buy-best-accounts.org/
marketplace for ready-made accounts https://social-accounts-marketplaces.live/
account trading service https://accounts-marketplace.live
account market social-accounts-marketplace.xyz
account market account marketplace
account exchange service https://buy-accounts-shop.pro
find accounts for sale https://accounts-marketplace.art/
guaranteed accounts https://buy-accounts.live
online account store https://accounts-marketplace.online
account buying service https://accounts-marketplace-best.pro/
купить аккаунт https://akkaunty-na-prodazhu.pro/
магазин аккаунтов https://rynok-akkauntov.top/
маркетплейс аккаунтов соцсетей kupit-akkaunt.xyz
биржа аккаунтов akkaunt-magazin.online
купить аккаунт akkaunty-market.live
купить аккаунт https://kupit-akkaunty-market.xyz/
маркетплейс аккаунтов akkaunty-optom.live
маркетплейс аккаунтов https://online-akkaunty-magazin.xyz
продажа аккаунтов https://akkaunty-dlya-prodazhi.pro
продажа аккаунтов https://kupit-akkaunt.online
buy facebook accounts for advertising https://buy-adsaccounts.work
facebook account buy https://buy-ad-accounts.click
buy facebook ads accounts buy aged facebook ads account
buy facebook advertising accounts https://buy-ads-account.click
buy facebook account https://ad-account-buy.top
buy facebook ads manager https://buy-ads-account.work/
buy facebook account for ads buying facebook accounts
buy facebook ad account https://buy-ad-account.click
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Подробнее можно узнать тут – https://medalkoblog.ru/
facebook ad account for sale https://ad-accounts-for-sale.work/
buy google ads agency account https://buy-ads-account.top
buy aged google ads accounts https://buy-ads-accounts.click
buy google ads account https://ads-account-for-sale.top
google ads agency account buy https://ads-account-buy.work
google ads accounts https://buy-ads-invoice-account.top/
buy google ads agency account https://buy-account-ads.work/
google ads agency accounts google ads agency account buy
facebook business manager for sale buy-business-manager.org
google ads agency accounts https://ads-agency-account-buy.click/
google ads account seller https://buy-verified-ads-account.work
buy facebook business manager account https://buy-business-manager-acc.org/
facebook bm for sale buy business manager account
buy facebook business manager buy-verified-business-manager-account.org
facebook business manager for sale https://buy-verified-business-manager.org/
verified bm for sale https://business-manager-for-sale.org/
facebook business manager account buy https://buy-business-manager-verified.org/
buy bm facebook buy-bm.org
buy business manager account https://verified-business-manager-for-sale.org
buy business manager https://buy-business-manager-accounts.org/
tiktok ads account for sale https://buy-tiktok-ads-account.org
tiktok ad accounts https://tiktok-ads-account-buy.org
buy tiktok ads accounts tiktok ad accounts
tiktok ads account for sale https://tiktok-agency-account-for-sale.org
tiktok agency account for sale https://buy-tiktok-ad-account.org
tiktok ads account buy tiktok agency account for sale
buy tiktok ads accounts https://buy-tiktok-business-account.org
tiktok ads agency account https://buy-tiktok-ads.org
tiktok agency account for sale https://tiktok-ads-agency-account.org
https://kampascher.shop/# kamagra oral jelly
se puede comprar silvederma sin receta: se puede comprar la pastilla del dÃa después sin receta en chile – requisitos para abrir una farmacia online en chile
logotipo farmacia online: Confia Pharma – promo farmacia online
xylocaina crema: etoricoxib 90 mg prezzo – ecoval crema prezzo
acheter cialis pharmacie sans ordonnance: anti-inflammatoire pour chien sans ordonnance en pharmacie – exemple ordonnance bas de contention
fentanil cerotto 12 mcg prezzo: loperamide hexal – farmacia online 24 recensioni
comprar diazepam sin receta m̩dica: comprar cialis original online sin receta Рrubifen farmacia online
tarif viagra: parakito roll on – aphrodisiaque sans ordonnance en pharmacie
monuril gГ©nГ©rique sans ordonnance: dГ©rivГ© amoxicilline sans ordonnance – acheter une pilule sans ordonnance
ordonnance cystite en ligne test covid en pharmacie sans ordonnance roger gallet fleur d’osmanthus
medicament pour perdre du poids sur ordonnance: Pharmacie Express – viagra homme 100 mg
traitement infections urinaires sans ordonnance: creme lavante avene – tadalafil prix 10mg
https://pharmacieexpress.com/# mГ©dicament perte de poids sans ordonnance
symbicort prezzo con ricetta: glucophage 500 prezzo – crema per taglietti intimi
produit otite sans ordonnance: Pharmacie Express – pharmacie en ligne cialis sans ordonnance
sans ordonnance infection urinaire coquelusedal ordonnance louer bГ©quille pharmacie sans ordonnance
l’ozempic sans ordonnance: Pharmacie Express – exemple ordonnance ventoline
farmacia online forum: kestine 10 mg prezzo – zoloder 200
tiras reactivas farmacia online Confia Pharma comprar vacuna gripe sin receta
urixana rosa: dicloreum 150 mg compresse – zhekort spray
traitement infection urinaire chat en pharmacie sans ordonnance: Г©quivalent solupred sans ordonnance – brosse Г dent gum
https://confiapharma.shop/# comprar sumial sin receta
farmacia online con receta migliore farmacia online cialis farmacia online espaГ±a barata
se puede comprar ibuprofeno sin receta 2023: farmacia online veterinaria codigo promocional – tiras reactivas farmacia online
mejor farmacia online 2016: farmacia bravi online – curso de auxiliar de farmacia online gratis
se puede comprar mebendazol sin receta se puede comprar viagra sin receta ? lexxema se puede comprar sin receta
redcare farmacia online: mejores tiendas online farmacia – comprar pastilla dia despues sin receta
yellox collirio: flixoderm crema – lasix costo
muscoril prezzo cerotti antidolorifici migliori siti farmacia affidabili
https://pharmacieexpress.shop/# produit verrue pharmacie sans ordonnance
topster supposte prezzo: Farmacia Subito – flixoderm crema prezzo
monuril prezzo: froben sciroppo 5 mg – farmacia top online
comprar benzetacil sin receta farmacia online fluconazol se puede comprar antibiГіtico sin receta en andorra
buy medicine online in india: india mail order pharmacy – best online pharmacy in india
mexican pharmacies that ship to us what can you buy in a mexican pharmacy drugs you can buy in mexico
medlife pharmacy: aster pharmacy india – drugs from india
https://pharmmex.com/# online medication ordering
ketamine online pharmacy: Pharm Express 24 – Copegus
india rx pharmacy prevacid online pharmacy klonopin online pharmacy reviews
mounjaro mexico approval: prescriptions in mexico – what are the best pharmacies in canada that ship to the us
metoprolol people’s pharmacy Pharm Express 24 order viagra online pharmacy
farmacia mexico online: pain management pharmacy – canadian pharmacies that ship to the us
buy adipex online pharmacy: get prescription online – leflunomide online pharmacy
https://pharmexpress24.shop/# pharmacy loratadine
india online medicine online pharmacy india best indian pharmacy
buy meds online: mexican online pharmacy wegovy – mounjaro mexico pharmacy
sun pharmacy india: doctor of pharmacy india – buy medicine online in india
mexican viagra pill Pharm Mex pharmacy in mexico online
http://pharmmex.com/# buy wegovy mexico
online medicines india: pharmacy online india – retail pharmacy market in india
india online pharmacy market: india medical – medicine delivery in vadodara
career after b pharmacy in india b pharmacy salary in india medlife pharmacy
viagra online mexican pharmacy: mexican pharmacy albuterol – mexican pill
Maxolon Pharm Express 24 viagra bangkok pharmacy
nexium mexico pharmacy: uk pharmacy online viagra – preferred plus pharmacy ibuprofen
https://pharmmex.shop/# cost of xanax in mexico
india drug store: п»їindia pharmacy – india pharmacy delivery
online pharmacy usa wholesale pharmacy online prescriptions online pharmacy
medplus pharmacy india: medicine online purchase – prescriptions from india
rx hmong pharmacy: central rx pharmacy – reputable online pharmacy cialis
reputable indian pharmacies wellbutrin indian pharmacy buy viagra from us pharmacy
your pharmacy ibuprofen: humana pharmacy store – women’s health
https://inpharm24.shop/# order medicine online india
can i buy viagra in mexico and bring it to the us: pharmacy store online – can i buy ozempic in mexico?
career after b pharmacy in india buy medicines online b pharmacy salary in india
clindamycin uk pharmacy: Pharm Express 24 – best online pharmacy propecia
can you buy zepbound in mexico retin a mexico pharmacy pain meds in mexico
buying viagra in mexico: Pharm Mex – fluconazole mexican pharmacy
best indian pharmacy: order medicines online – india pharmacy online
https://pharmexpress24.com/# marketplace oak harbor wa pharmacy store number
medicine online order india rx online medicine in india
mexico pharmacy price list adderall: buy semaglutide online mexico – tirzepatide cost in mexico
online pharmacy no prescription concerta best pharmacy to buy viagra alliance rx pharmacy
nps online pharmacy: Pharm Express 24 – Florinef
viagra 100mg online canada: cheap viagra pills – online generic viagra
lowest price viagra uk average price of generic viagra viagra prescription coupon
sildenafil soft 100mg: generic india viagra – viagra generic in united states
https://vgrsources.com/# buy viagra online legally
buy viagra online with mastercard: VGR Sources – where to buy female viagra
sildenafil 100 mg tablet coupon VGR Sources viagra canada price
citrate sildenafil: viagra generic online pharmacy – buy viagra in canada
sildenafil 20 mg sale: viagra online pharmacies – sildenafil 90 mg
https://vgrsources.com/# australia online pharmacy viagra
viagra 88 VGR Sources where can i buy sildenafil 20mg
viagra price pharmacy: otc sildenafil 20 mg tablets – viagra online price
female viagra sale in singapore: VGR Sources – buy real viagra online
sildenafil cheapest price Preis Viagra 50 mg viagra 75 mg
canada drug sildenafil: viagra 50mg online in india – viagra price singapore
where to buy real viagra: VGR Sources – generic viagra without rx
https://vgrsources.com/# female viagra pill price in india
buy viagra australia VGR Sources sildenafil 150 mg online
where can you get generic viagra: VGR Sources – canadian viagra paypal
sildenafil 50 mg online us: buy viagra with discover card – buy viagra australia online
viagra online canada mastercard VGR Sources viagra tablets for men
generic sildenafil 40 mg: viagra online europe – viagra cost australia
viagra 150 tablet: female viagra pills in south africa – sildenafil tablets 100mg online
https://vgrsources.com/# genuine viagra online uk
viagra online canada no prescription viagra where to buy canada sildenafil over the counter australia
where to buy cheap sildenafil: VGR Sources – best viagra in usa
viagra tablet online purchase: viagra brand name in india – female viagra south africa
female viagra pill VGR Sources female viagra prescription
buy real viagra online uk: VGR Sources – viagra prescription cost uk
prescription viagra online usa: sildenafil 100mg from india – sildenafil 50 mg no prescription
https://vgrsources.com/# online viagra from canada
real viagra for sale sildenafil 1mg viagra online from utah
generic viagra soft gel capsule: viagra tablets for men – cost of female viagra
how much is female viagra: online generic viagra – sildenafil citrate australia
female viagra real sildenafil otc usa uk viagra no prescription
where to buy viagra in us: VGR Sources – where to buy female viagra canada
buy viagra in usa online: VGR Sources – cheap viagra 150 mg
buy generic viagra online india: VGR Sources – where can i buy viagra online
https://vgrsources.com/# how to get viagra online in usa
sildenafil 100 mg generic price VGR Sources sildenafil 100 mg uk
buy sildenafil over the counter: how to get viagra prescription – online pharmacy for viagra
viagra online with prescription: viagra for sale no prescription – buy brand viagra online australia
can i buy viagra in mexico: VGR Sources – sildenafil 2.5 mg
female viagra pill canada sildenafil tablet brand name in india where can i get female viagra in australia
sildenafil 20 mg online canada: VGR Sources – purchase sildenafil citrate 100mg
sildenafil 88: where can you get female viagra pills – sildenafil 100mg prescription
online viagra: VGR Sources – purchase viagra usa
brand viagra 50mg online VGR Sources best price for sildenafil 50 mg
https://vgrsources.com/# buy viagra levitra
buy sildenafil online safely: VGR Sources – viagra online canada generic
can i buy viagra over the counter nz: VGR Sources – viagra kaufen
where to buy viagra online in australia: VGR Sources – sildenafil 100 mg tablet usa
viagra 25mg price buy cheap viagra india viagra 100 coupon
cheap viagra: sildenafil generic 100 mg – cheap viagra online canadian pharmacy
viagra for sale in usa: us online pharmacy viagra – sildenafil 25 mg coupon
generic viagra online uk: female viagra – buy generic sildenafil uk
CrestorPharm: 5 mg rosuvastatin – can rosuvastatin 20 mg be cut in half
http://crestorpharm.com/# Crestor Pharm
FDA-approved Rybelsus alternative SemagluPharm Safe delivery in the US
Generic Crestor for high cholesterol: side effects of crestor – Crestor home delivery USA
LipiPharm: Lipi Pharm – LipiPharm
crestor and paxlovid: CrestorPharm – Rosuvastatin tablets without doctor approval
PredniPharm: Predni Pharm – PredniPharm
buy prednisone nz PredniPharm 50 mg prednisone canada pharmacy
Online statin drugs no doctor visit: Lipi Pharm – Lipi Pharm
https://crestorpharm.shop/# Crestor 10mg / 20mg / 40mg online
does rybelsus cause acid reflux: SemagluPharm – Semaglu Pharm
Crestor mail order USA: Over-the-counter Crestor USA – CrestorPharm
LipiPharm Safe atorvastatin purchase without RX Online statin drugs no doctor visit
Lipi Pharm: LipiPharm – Lipi Pharm
Lipi Pharm: Lipi Pharm – statin lipitor
LipiPharm: Safe atorvastatin purchase without RX – Safe atorvastatin purchase without RX
SemagluPharm SemagluPharm Semaglu Pharm
https://lipipharm.com/# Lipi Pharm
PredniPharm: PredniPharm – Predni Pharm
PredniPharm: PredniPharm – Predni Pharm
Crestor Pharm Generic Crestor for high cholesterol Buy statins online discreet shipping
Semaglu Pharm: Semaglu Pharm – rybelsus 3mg weight loss
semaglutide to tirzepatide conversion: Online pharmacy Rybelsus – No prescription diabetes meds online
USA-based pharmacy Lipitor delivery Lipi Pharm Lipi Pharm
Rosuvastatin tablets without doctor approval: price of crestor 5mg – Crestor Pharm
atorvastatin when to take: can atorvastatin cause dry mouth – USA-based pharmacy Lipitor delivery
semaglutide brands: should i switch from semaglutide to tirzepatide – Order Rybelsus discreetly
how long does atorvastatin stay in your system Lipi Pharm USA-based pharmacy Lipitor delivery
buy prednisone online without a prescription: prednisone 30 mg – prednisone 10mg buy online
Over-the-counter Crestor USA: CrestorPharm – Crestor Pharm
generic prednisone cost: prednisone 20 mg tablets – prednisone 5 mg brand name
https://semaglupharm.com/# SemagluPharm
prednisone medicine: PredniPharm – canada buy prednisone online
prednisone 20mg: mail order prednisone – PredniPharm
rybelsus 3 mg tablet: SemagluPharm – SemagluPharm
LipiPharm why should i not take atorvastatin Affordable Lipitor alternatives USA
п»їBuy Crestor without prescription: CrestorPharm – why take crestor at bedtime
prednisone brand name canada: Predni Pharm – PredniPharm
stopping lipitor suddenly side effects LipiPharm Lipi Pharm
https://lipipharm.shop/# Lipi Pharm
Lipi Pharm: LipiPharm – Lipi Pharm
lipitor lawsuit settlement amounts how much is lipitor without insurance Lipi Pharm
side effects of atorvastatin 10 mg: Lipi Pharm – lipitor grapefruit
does crestor cause back pain: Online statin therapy without RX – what is rosuvastatin 10 mg used for
Crestor 10mg / 20mg / 40mg online п»їBuy Crestor without prescription does crestor cause dry mouth
PredniPharm: PredniPharm – PredniPharm
http://lipipharm.com/# Lipi Pharm
Best price for Crestor online USA: Crestor 10mg / 20mg / 40mg online – Buy cholesterol medicine online cheap
http://semaglupharm.com/# FDA-approved Rybelsus alternative
https://crestorpharm.com/# CrestorPharm
Crestor Pharm: Crestor Pharm – can you drink coffee with crestor
Predni Pharm Predni Pharm Predni Pharm
5 mg prednisone daily: generic prednisone online – prednisone brand name india
https://semaglupharm.com/# rybelsus and pancreatitis
SemagluPharm: SemagluPharm – rybelsus order online
Predni Pharm prednisone pill prices prednisone 30 mg daily
https://semaglupharm.shop/# Semaglu Pharm
LipiPharm: Lipi Pharm – can i stop lipitor cold turkey
https://lipipharm.com/# Lipi Pharm
prednisone 25mg from canada: no prescription prednisone canadian pharmacy – Predni Pharm
https://semaglupharm.com/# 10mg semaglutide dosage chart
Crestor Pharm Affordable cholesterol-lowering pills crestor diabetes
SemagluPharm: semaglutide and alcohol – No prescription diabetes meds online
can rosuvastatin cause anxiety: CrestorPharm – Crestor Pharm
https://semaglupharm.shop/# Semaglu Pharm
prednisone over the counter australia PredniPharm prednisone 2.5 mg tab
PredniPharm: PredniPharm – where to buy prednisone in canada
http://prednipharm.com/# PredniPharm
CrestorPharm: Crestor 10mg / 20mg / 40mg online – Crestor Pharm
http://semaglupharm.com/# Online pharmacy Rybelsus
Crestor 10mg / 20mg / 40mg online CrestorPharm can you cut rosuvastatin 20 mg in half
Generic Lipitor fast delivery: LipiPharm – Lipi Pharm
CrestorPharm: CrestorPharm – can rosuvastatin cause neuropathy
https://semaglupharm.com/# Semaglutide tablets without prescription
п»їBuy Rybelsus online USA: online semaglutide prescription – SemagluPharm
SemagluPharm п»їBuy Rybelsus online USA SemagluPharm
https://semaglupharm.com/# Semaglutide tablets without prescription
CrestorPharm: why was rosuvastatin taken off the market? – high intensity rosuvastatin
https://lipipharm.com/# LipiPharm
20 mg of prednisone: PredniPharm – PredniPharm
Predni Pharm prednisone 50 mg tablet canada Predni Pharm
https://semaglupharm.com/# FDA-approved Rybelsus alternative
PredniPharm: PredniPharm – PredniPharm
Semaglu Pharm: Semaglu Pharm – Where to buy Semaglutide legally
weight loss injections semaglutide Semaglu Pharm constipation with semaglutide
https://semaglupharm.com/# SemagluPharm
Semaglu Pharm: is wegovy semaglutide – Semaglu Pharm
semaglutide weight loss clinic near me can you lose weight with rybelsus Rybelsus online pharmacy reviews
Crestor Pharm: can you take lipitor and crestor together – CrestorPharm
https://lipipharm.com/# Lipi Pharm
https://semaglupharm.com/# Buy Rybelsus online USA
Safe online pharmacy for Crestor: Crestor mail order USA – Crestor Pharm
meme crestor CrestorPharm Rosuvastatin tablets without doctor approval
PredniPharm: PredniPharm – prednisone 50 mg tablet canada
https://semaglupharm.com/# how long is semaglutide good for in the fridge
SemagluPharm: Affordable Rybelsus price – Where to buy Semaglutide legally
¡Hola, estrategas del azar !
Mejores casinos online extranjeros con beneficios diarios – https://www.casinoextranjerosespana.es/# п»їcasinos online extranjeros
¡Que disfrutes de asombrosas tiradas exitosas !
Lipi Pharm: does lipitor cause anxiety – atorvastatin 40 mg c3
lipitor high blood pressure lipitor package insert pdf can you stop taking atorvastatin cold turkey
https://semaglupharm.com/# SemagluPharm
https://semaglupharm.com/# Online pharmacy Rybelsus
No doctor visit required statins: rosuvastatin 20mg – CrestorPharm
https://semaglupharm.shop/# Semaglu Pharm
Safe atorvastatin purchase without RX Generic Lipitor fast delivery LipiPharm
thecanadianpharmacy: medication canadian pharmacy – best rated canadian pharmacy
Meds From Mexico: Meds From Mexico – purple pharmacy mexico price list
https://indiapharmglobal.com/# legitimate online pharmacies india
canadian neighbor pharmacy: Canada Pharm Global – canadian pharmacy
India Pharm Global India Pharm Global online pharmacy india
http://indiapharmglobal.com/# India Pharm Global
https://medsfrommexico.shop/# Meds From Mexico
best canadian pharmacy to order from: canada pharmacy world – best online canadian pharmacy
Meds From Mexico: mexican mail order pharmacies – Meds From Mexico
Meds From Mexico mexican rx online Meds From Mexico
https://medsfrommexico.shop/# Meds From Mexico
mexico drug stores pharmacies: Meds From Mexico – Meds From Mexico
Meds From Mexico: mexican pharmaceuticals online – buying prescription drugs in mexico online
http://canadapharmglobal.com/# legitimate canadian pharmacies
canadian pharmacy world Canada Pharm Global legit canadian pharmacy online
http://medsfrommexico.com/# mexican border pharmacies shipping to usa
¡Saludos, descubridores de oportunidades !
Casino online extranjero con sistema de lealtad – https://www.casinosextranjerosenespana.es/ casinosextranjerosenespana.es
¡Que vivas increíbles instantes inolvidables !
¡Hola, usuarios de sitios de juego !
Casinossinlicenciaespana.es – Comparte tu opiniГіn – https://www.casinossinlicenciaespana.es/ casino sin licencia espaГ±a
¡Que experimentes rondas emocionantes !
India Pharm Global: reputable indian pharmacies – India Pharm Global
canadian mail order pharmacy: Canada Pharm Global – canadian mail order pharmacy
indian pharmacy online India Pharm Global India Pharm Global
https://medsfrommexico.com/# mexican drugstore online
India Pharm Global: India Pharm Global – India Pharm Global
https://canadapharmglobal.com/# canadian pharmacies
Meds From Mexico: mexican pharmaceuticals online – Meds From Mexico
online canadian pharmacy Canada Pharm Global ed drugs online from canada
https://indiapharmglobal.shop/# indian pharmacy online
India Pharm Global: best online pharmacy india – indian pharmacy paypal
canada drugs: Canada Pharm Global – ed meds online canada
canadian pharmacy oxycodone Canada Pharm Global canadian discount pharmacy
https://medsfrommexico.com/# Meds From Mexico
mexico drug stores pharmacies: Meds From Mexico – buying prescription drugs in mexico online
https://indiapharmglobal.com/# India Pharm Global
Meds From Mexico: mexican drugstore online – Meds From Mexico
https://medsfrommexico.com/# Meds From Mexico
canadian valley pharmacy Canada Pharm Global canadapharmacyonline legit
canadian drug pharmacy: Canada Pharm Global – northern pharmacy canada
¡Hola, amantes del ocio !
Casino por fuera con sistemas de seguridad SSL – https://casinoonlinefueradeespanol.xyz/# casino por fuera
¡Que disfrutes de asombrosas movidas brillantes !
https://canadapharmglobal.shop/# online canadian pharmacy
Meds From Mexico: medication from mexico pharmacy – Meds From Mexico
mexico drug stores pharmacies mexican rx online mexican pharmaceuticals online
reputable indian online pharmacy: India Pharm Global – india online pharmacy
¡Saludos, estrategas del riesgo !
Comparativa de tragaperras en casinos extranjeros – https://www.casinoextranjerosenespana.es/ mejores casinos online extranjeros
¡Que disfrutes de jackpots impresionantes!
https://efarmaciait.shop/# dati ted
https://raskapotek.shop/# Rask Apotek
borvann apotek Rask Apotek sjampo mot flass apotek
Svenska Pharma: apotek login – Svenska Pharma
https://efarmaciait.com/# EFarmaciaIt
Papa Farma Papa Farma Papa Farma
Rask Apotek: tubeklemmer apotek – Rask Apotek
Svenska Pharma: apotek ombud – Svenska Pharma
https://raskapotek.com/# Rask Apotek
https://papafarma.shop/# Papa Farma
sömntabletter apotek naproxen tabletter Svenska Pharma
Rask Apotek: Rask Apotek – Rask Apotek
http://svenskapharma.com/# Svenska Pharma
Rask Apotek Rask Apotek influensavaksine apotek 2022
http://raskapotek.com/# Rask Apotek
Rask Apotek: gentest apotek – tannregulering strikk apotek
https://raskapotek.shop/# hvorfor er det begrensninger i hvor mye medisin et apotek kan utlevere på blå resept
EFarmaciaIt: EFarmaciaIt – nuvaring confezione da 3
farmasГёyt apotek Rask Apotek piercing nГҐl apotek
Г¶rter naturens eget apotek: Svenska Pharma – apotek tandborste
http://raskapotek.com/# diabetes test apotek
¡Saludos, amantes de la diversión !
casino online extranjero que acepta Neteller – https://casinosextranjero.es/# casinos extranjeros
¡Que vivas increíbles jugadas excepcionales !
http://raskapotek.com/# nese voks apotek
Svenska Pharma: apottek – amningsbh med bygel
EFarmaciaIt EFarmaciaIt EFarmaciaIt
Papa Farma: Papa Farma – erps one comprimidos para que sirve
http://raskapotek.com/# apotek levering
EFarmaciaIt: EFarmaciaIt – 10% di 800
apotek ГҐpningstider sГёndag: Rask Apotek – dyvelsdrek apotek
trausan 1000 EFarmaciaIt augmentin compresse costo
https://raskapotek.com/# Rask Apotek
https://papafarma.com/# Papa Farma
https://papafarma.com/# Papa Farma
casenlax embarazo: Papa Farma – farma
productos sanitarios parafarmacia fisio solares bb cream isdin opiniones
apotek stan: bГ¤sta schampo mot svamp i hГҐrbotten – paracetamol pris
https://svenskapharma.com/# Svenska Pharma
Rask Apotek: Rask Apotek – apotek ГҐpen nГҐ
EFarmaciaIt EFarmaciaIt scalapay servizio clienti
Svenska Pharma: ashwagandha apotek – Г¶ppet apotek
¡Hola, amantes del entretenimiento !
Casinos extranjeros que aceptan jugadores europeos – https://casinoextranjero.es/# casinos extranjeros
¡Que vivas oportunidades irrepetibles !
http://efarmaciait.com/# EFarmaciaIt
http://svenskapharma.com/# covid antigen test apotek
EFarmaciaIt: farma max – neurania recensioni
Rask Apotek allergitest apotek Rask Apotek
risparmia in farmacia recensioni: vitamina c in gravidanza forum – EFarmaciaIt
https://raskapotek.shop/# kompresjon arm apotek
EFarmaciaIt: EFarmaciaIt – EFarmaciaIt
dildo billig Svenska Pharma Svenska Pharma
antigripal barato: Papa Farma – Papa Farma
https://papafarma.com/# comprar productos de farmacia online
https://svenskapharma.shop/# apotek express
Rask Apotek: Rask Apotek – nГ¦ringsdrikke apotek
svamp tassar hund apotek ansiktsmask tyg apotek skena finger apotek
https://svenskapharma.com/# Svenska Pharma
Pharma Jetzt: versandapotheke versandkostenfrei – apotek online
Medicijn Punt: pharmacy online netherlands – MedicijnPunt
PharmaJetzt online apotheke gГјnstig PharmaJetzt
http://pharmaconnectusa.com/# ambien pharmacy no prescription
Pharma Connect USA: ciprofloxacin online pharmacy – PharmaConnectUSA
MedicijnPunt: internetapotheek – Medicijn Punt
http://pharmaconnectusa.com/# PharmaConnectUSA
http://pharmajetzt.com/# apotheke bestellen
Pharma Confiance Pharma Confiance produits parapharmacie les plus vendus
¡Saludos, descubridores de tesoros!
casino fuera de EspaГ±a con tragamonedas 3D – п»їhttps://casinosonlinefueraespanol.xyz/ casinos fuera de espaГ±a
¡Que disfrutes de instantes inolvidables !
PharmaJetzt: PharmaJetzt – apothek online
https://pharmaconfiance.shop/# Pharma Confiance
Medicijn Punt: de apotheker – apotheke holland
Pharma Jetzt apotheke internet PharmaJetzt
https://pharmajetzt.com/# versandapotheke gГјnstig
Medicijn Punt: MedicijnPunt – MedicijnPunt
https://pharmajetzt.shop/# PharmaJetzt
safe online pharmacy: lexapro pharmacy online – pharmacy cialis prices
antibiotica kopen zonder recept MedicijnPunt MedicijnPunt
Medicijn Punt: MedicijnPunt – Medicijn Punt
https://medicijnpunt.com/# apotheek kopen
PharmaConnectUSA: viagra phuket pharmacy – target pharmacy finasteride
inhouse pharmacy general motilium target pharmacy crestor PharmaConnectUSA
https://pharmajetzt.com/# online apotheke
https://pharmaconfiance.shop/# Pharma Confiance
online pharmacy uk: express rx pharmacy and medical supplies – online pharmacy checker
Pharma Connect USA: singapore online pharmacy – PharmaConnectUSA
PharmaConnectUSA pharmacy price of percocet maxalt mlt online pharmacy
https://pharmajetzt.shop/# wegovy online apotheke
lortab pharmacy online: PharmaConnectUSA – terbinafine target pharmacy
Medicijn Punt: Medicijn Punt – online medicijnen bestellen met recept
mГ©dicaments en ligne Pharma Confiance acheter vaccin chat en ligne
https://medicijnpunt.shop/# medicijnen online bestellen
¡Hola, cazadores de recompensas excepcionales!
Casino online extranjero con pagos por Skrill – п»їhttps://casinosextranjerosdeespana.es/ casinosextranjerosdeespana.es
¡Que vivas increíbles victorias memorables !
apotheke online shop: Pharma Jetzt – luitpold apotheke online-shop versandapotheke
https://pharmaconnectusa.com/# PharmaConnectUSA
PharmaJetzt: internet apotheke test – Pharma Jetzt
apotheke online MedicijnPunt Medicijn Punt
http://pharmajetzt.com/# internetapotheke selbitz
apteka nl online: farmacie online – MedicijnPunt
medicijnen bestellen online: online apotheek nederland met recept – Medicijn Punt
https://medicijnpunt.shop/# snel medicijnen bestellen
luidpold apotheke Pharma Jetzt PharmaJetzt
apotheek aan huis: internetapotheek spanje – medicijn online
https://pharmaconnectusa.shop/# cipro pharmacy
https://medicijnpunt.shop/# MedicijnPunt
medikamente online bestellen: online apotheke kostenloser versand – PharmaJetzt
apotheke online gГјnstig bestellen Pharma Jetzt shop apothe
PharmaConnectUSA: people’s pharmacy zoloft – lamisil pharmacy uk
http://pharmaconnectusa.com/# Pharma Connect USA
chez dГ©dГ©: Pharma Confiance – effet ketoprofene
MedicijnPunt apotheek spanje online Medicijn Punt
Pharma Confiance: pharmacie de garde orange ouverte aujourd’hui – ketoprofene et efferalgan
https://pharmaconnectusa.com/# viagra registered pharmacy
https://medicijnpunt.com/# apotheek winkel 24 review
medicijnen op recept online bestellen: MedicijnPunt – Medicijn Punt
Pharma Jetzt shopapptheke medikamente bestellen ohne rezept
apotheke auf rechnung bestellen: apotheke online – pzn apotheke
http://pharmaconnectusa.com/# coumadin pharmacy
MedicijnPunt: MedicijnPunt – internet apotheek
Pharma Jetzt PharmaJetzt apotheke online shop
PharmaConnectUSA: PharmaConnectUSA – albertsons pharmacy
http://pharmaconfiance.com/# phamacie en ligne
?Hola, seguidores del exito !
Casino por fuera con pagos en criptodivisas – https://www.casinosonlinefueradeespanol.xyz/# casinos online fuera de espaГ±a
?Que disfrutes de asombrosas tiradas brillantes !
https://pharmaconfiance.com/# sun medical marseille
Pharma Jetzt: liefer apotheke – online apotheke versandkostenfrei
Pharma Confiance Pharma Confiance Pharma Confiance
l’ordre national des pharmaciens: doliprane en parapharmacie – rouen pharmacie
https://pharmaconfiance.shop/# Pharma Confiance
Pharma Connect USA: cheap cialis online pharmacy – Pharma Connect USA
PharmaConnectUSA: Pharma Connect USA – tamoxifen pharmacy
https://pharmajetzt.shop/# PharmaJetzt
Pharma Jetzt: apotheke shop online – Pharma Jetzt
PharmaJetzt: PharmaJetzt – PharmaJetzt
https://pharmajetzt.com/# Pharma Jetzt
https://pharmajetzt.com/# ipill apotheke versandkostenfrei
pha pompes: Pharma Confiance – Pharma Confiance
Pharma Connect USA: tacrolimus pharmacy – Pharma Connect USA
https://pharmaconnectusa.com/# vons pharmacy
versand apotheke: arzneimittel kaufen – Pharma Jetzt
https://pharmajetzt.com/# medikamente online bestellen auf rechnung
Medicijn Punt: medicijnen apotheek – Medicijn Punt
http://pharmaconfiance.com/# Pharma Confiance
https://medicijnpunt.com/# MedicijnPunt
place du jour grossiste: nutri prescription – pharmacie homГ©opathie paris 15
Pharma Confiance: Pharma Confiance – Pharma Confiance
https://pharmajetzt.shop/# online apotheke germany
apteka nl online: MedicijnPunt – online apotheek zonder recept ervaringen
Pharma Confiance: Pharma Confiance – ma pharmacie en ligne
https://medicijnpunt.com/# apteka online holandia
http://pharmaconnectusa.com/# PharmaConnectUSA
PharmaJetzt: aptheke – Pharma Jetzt
MedicijnPunt: MedicijnPunt – Medicijn Punt
https://pharmaconfiance.shop/# Pharma Confiance
Pharma Jetzt: apothekenversand – shop apotheke berlin
Pharma Connect USA: Pharma Connect USA – online pharmacy accutane no prescription
Pharma Confiance: Pharma Confiance – parapharmacie c’est quoi
http://medicijnpunt.com/# medicijnen aanvragen apotheek
Pharma Jetzt: apotheke onlineshop – shoop apotheke
Medicijn Punt: medicijnen kopen met ideal – MedicijnPunt
pharmacie 18: combien coute du viagra – pharmacie orthopГ©die autour de moi
http://pharmaconnectusa.com/# Primaquine