
最近刷到不少声音,说”Agent 时代来了,工作流要被淘汰了”。
说实话,我刚听到这个说法的时候,内心是有一点动摇的。毕竟我这大半年一直在用 n8n 搞各种自动化:YouTube 评论雷达、Reddit 选题监控、公众号数据抓取……跑得好好的,突然有人告诉你这条路要废了?
但是真正把 Agent 用起来之后,我发现这个问题本身就问错了。工作流和 Agent 不是替代关系,它们解决的是完全不同类型的问题。
与其纠结”谁更先进”,不如想清楚一个更实际的问题:你的业务,你手上这件事,到底需要什么,是”步骤固定、需要稳定执行”,还是”信息残缺、需要来回补全”?毕竟,不能为了用工具而用。
先说结论:一个管”确定的事”,一个管”不确定的事”
我自己的体感总结就两句话:
①工作流(n8n、Dify 编排)= 流水线:有固定的步骤、路径清晰、出了问题一眼能看到哪一步挂了。
②Agent(支持多轮对话的 AI 助手)= 协作者:你能追问、可以理解模糊表达、能记住你上一句说了什么、能处理你说到一半改口的情况。
它们不是竞争对手,更像是一个团队里的两个角色,一个是执行力极强的项目经理,一个是沟通能力超强的业务顾问。
稍微聊深一点:有哪些地方不一样?
不搞太专业的学术对比,就聊聊我实际用下来碰到的最明显的几个差异。
1、 输入是标准的,还是”随意说”的?
工作流天然适合处理”规整的输入”:API 返回的 JSON、定时抓取的数据、固定格式的表单。你在 n8n 里拖几个节点,数据就像水流一样从上游淌到下游,中间加个 AI 节点做摘要分析,最后写进多维表格,整个链路就清清楚楚。
如果输入是”用户随口说的一段话”、”拍了张照片”、”发了条语音”呢?处理这些非标准输入,工作流也是可以做的,用多模态 API 识图、调 ASR 转语音,但是一旦信息不全、用户说了一半、或者说完又改了,工作流就很难优雅地”追回来”。
Agent 的核心优势不是”能看图听声音”,而是”能记住上下文、追问、纠错、处理改口”。这才是工作流节点做不到的事。
2、过程需不需要”来回聊”?
这是我认为最核心的区分点。
工作流不是不能等用户回复,n8n 的 Webhook 节点就可以暂停流程,等外部触发再继续。但问题在于:你需要提前把所有可能的对话路径都设计成节点和条件分支。对话轮次一多、用户的回答稍微出格一点,节点图就会变得非常复杂,维护起来很痛苦。
Agent 的优势就在这里,多轮状态管理是它的本职工作,不需要你提前枚举所有分支,用户怎么说它都能接住。
3、出了问题,好不好查?
这是工作流的绝对优势。n8n 每个节点的输入输出都能看到,哪一步报错、返回了什么数据、是接口的问题还是数据格式的问题,一目了然。
Agent 这方面的成本要高一些。现在主流的 Agent 平台都有运行日志和 Trace 功能,过程不是完全不能查,但 LLM 的推理本质上是概率生成的,同样的输入不保证走同样的路径。你排查一个问题,可能需要反复跑几次才能复现,这和工作流”确定性执行、必现 bug”的调试体验差距很大。
4、成本和速度
工作流调的接口是固定的,跑一次消耗多少 Token、多少 API 调用,基本可预测。
Agent 的消耗取决于任务复杂度:简单的单步 Agent 可能只比工作流多一两成;但如果是多步规划、边执行边反思的那种 Agent,成本可能是工作流的 3 到 10 倍,而且每次波动较大。如果你的场景是每天批量跑上百次,这个差距会很明显。

举几个实际的案例
如果你是工作流和agent的深度用户,你一定理解我上面说的这四点,如果你不是很理解,没关系,我们找几个实际的案例来对比对比。
案例一:YouTube 评论选题雷达
这个例子是讲用工作流的优势。
我之前搭了一条 n8n 流程:每周定时触发 → 按关键词搜索 YouTube 视频 → 拉取热门评论 → 用 DeepSeek 分析评论里的痛点和选题方向 → 结构化结果写入飞书多维表格。
这个场景有两个关键特征:每一步都是确定的,而且我特别需要可追溯性。
如果某一周数据不对,我要能看到是搜索接口没返回数据、评论解析出了问题,还是 AI 分析的 prompt 需要调整。n8n 的节点化设计让我能精确定位到具体环节。
如果这件事交给 Agent 去”自己全程搞定”,它可能也能给我结果,但我会不放心:它到底搜了几页?去重逻辑对不对?评论是不是都拉全了?这些执行细节我没法确认。
当然,如果有人在工作流外面再套一层 Agent 做”结果校验和异常判断”,是可以的,这就是后面要说的混合模式。但执行层本身,工作流是最稳的选择。
案例二:采购信息录入多维表格
这个例子是讲用agent的优势。
之前给朋友搞了一个飞书多维表格,记录他日常的一些材料采购信息。经常在外跑并且要及时录信息的朋友会知道,要是打开表格一个字段一个字段的去录,太麻烦了。
所以实际的使用场景一定是:有时候拍张采购单据,有时候说几个关键词,比如打几个字”螺丝 M6 100个 3毛”,有时候发段语言。
这种场景用工作流来做,会非常难受。根本原因不是”没法处理图片或语音”,而是:
- 信息经常不全(没说供应商、没说单位)
- 我还会改口(”刚才说 100 个,其实要 200″)
- 字段补全的方式每次都不一样,没法提前穷举分支
它的信息数据是非标准化的,需要多轮对话和澄清,直到最后的数据满足写入多维表格的数据结构。
Agent 处理这个就很自然:接收我的随意输入 → 识别已有字段 → 追问缺失的部分 → 处理我的改口 → 最终确认输出标准化字段。
Agent 的核心价值在这里:多轮对话状态管理,让”人话”一步步变成”系统能理解的结构化数据”。
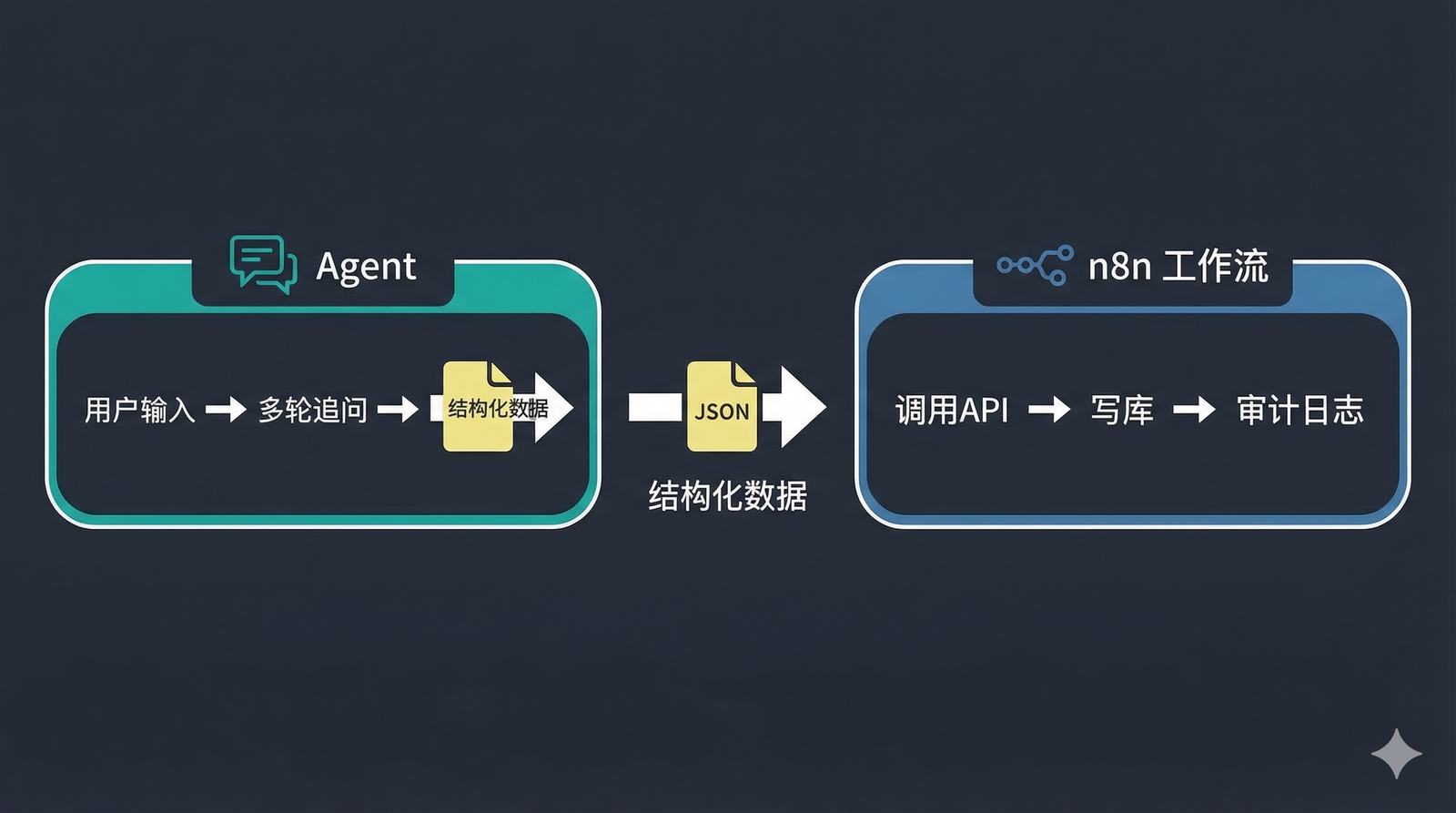
案例三:发起出差流程(Agent + 工作流配合)
这个例子是讲用Agent + 工作流配合的场景
有一个有意思的一个场景,也是”两者配合”的典型。比如我在公司内部,要搞一个用AI提交出差申请的机器人。
用户说了一句”我要去上海出差”,但 OA 系统的出差流程需要一堆字段:出发日期、返回日期、事由、是否订机票、预算范围……这一定是一个多轮会话的过程。
那么前半段我们可以用 Agent:
- 用户随口一说
- Agent 追问缺失字段:”什么时候去?大概几天?需要订机票吗?”
- 用户改口:”时间改到下周三”
- Agent 处理改口,最终输出一份完整的结构化数据
后半段就可以交给n8n:
- 接收 Agent 输出的标准化字段
- 调 OA 系统 API 创建出差申请
- 调知识库校验出差规则
- 创建失败时,自动重试并告警
为什么后半段不让 Agent 继续做?因为”调系统接口、处理失败重试”这些事情,需要确定性。尤其是在企业流程的场景上。
同样的输入,必须产生同样的结果,出了问题必须有迹可查。这些是工作流的本职,而不是 Agent 的强项。
Agent 负责”把人话变成标准字段”,工作流负责”把标准字段变成可审计的系统动作”。这是配合使用的核心分工。
那到底什么时候用谁?
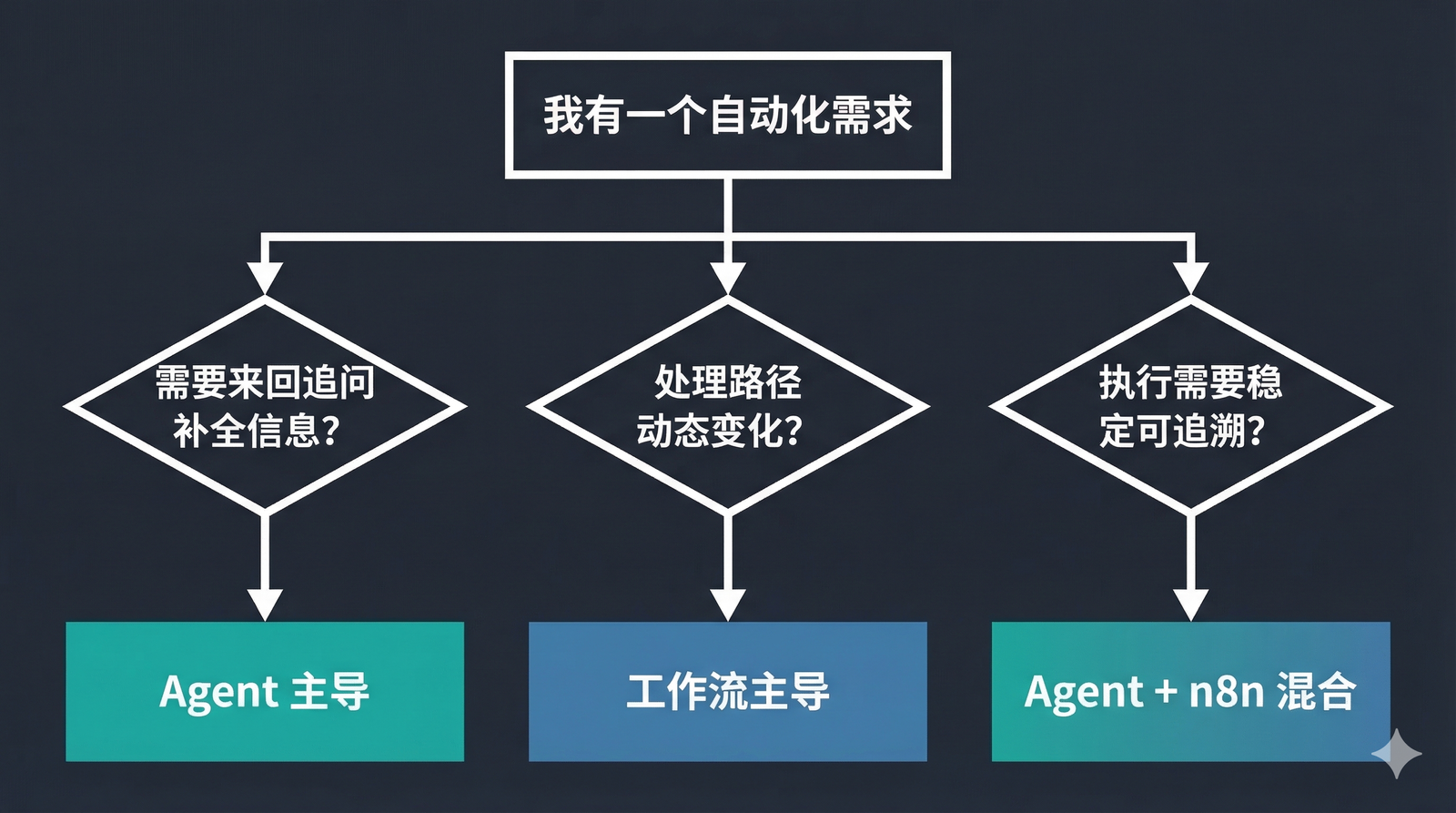
我自己总结了一个判断方法,可以问自己三个问题:
第一问:这件事需要”来回追问”才能把信息凑齐吗?
- 需要,且对话路径复杂多变 → Agent 主导
- 不需要,输入是固定或半固定的 → 工作流主导
第二问:执行动作需要稳定、可追溯、支持重试吗?
- 需要 → 工作流负责执行
- 只是给个建议或草稿,不直接操作系统 → Agent 自己就够了
第三问:这件事的处理路径,每次都需要动态决定吗?
- 处理逻辑每次都不一样,需要临时判断 → Agent 更合适
- 处理逻辑固定,哪怕输入每次不同 → 工作流就够了,不必引入 Agent 的不确定性
如果三个问题的答案是”前面需要对话补全,后面需要稳定执行”——那就是 Agent + 工作流混合架构的最佳场景。
写在最后
回到开头那个问题:自动化工作流过时了吗?我的回答是:完全没有。
目前生产环境里,绝大多数企业级自动化系统依然以工作流为主。原因很简单:确定性、可审计、成本可控。Agent 正在快速成熟,但它更像是一个新的能力层,而不是工作流的替代品。两者最优的组合方式,业内现在有个说法叫 “以工作流为骨架,以 Agent 为肌肉”:整体流程的路由、审批、通知、写库这些确定性动作,用工作流来串;某些需要理解自然语言、多轮追问、动态判断的节点,嵌入 Agent 来处理。
这样既保留了工作流的可见性和可控性,又能用上 Agent 的灵活性。一旦出了问题,也能精确定位:是执行层的工作流出了错,还是某个 Agent 节点的对话理解有偏差,而不是面对一个整体黑盒束手无策。现在缺的不是工具,而是搞清楚哪件事该交给谁。

