
如何把小红书里用关键词搜索出来的笔记结果都提取出来,保存在一个表格里?
手动一条一条复制肯定是不现实,对于这种重复有规则的工作,有没有什么自动化的方法解决?
试试RPA工具,今天我们就来用影刀RPA来玩一下,把小红书的笔记结果自动提取保存下来。
这些笔记其实挺有用处的,你可以通过点赞数、收藏数等,来初步判断什么样的笔记受欢迎,这些笔记的写作方式都是怎样的。
我们今天先用影刀RPA做一个简单初步的小红书笔记提取机器人,入个门玩玩。
影刀RPA:https://www.yingdao.com/ 官网免费下载就行。免费功能也基本够用。 (我用的是付费版的)。 下载注册什么的就不具体说了。
下载完成后我们创建一个应用,然后在自动化配置页面进行配置。

下面我们拆解下步骤,来说说具体如何配置。
一、打开网页
1、打开网页
首先,我们要让RPA先帮我们打开小红书的网页。
我们在网页自动化里,找到打开网页的指令,拖拽到中间的流程区域。
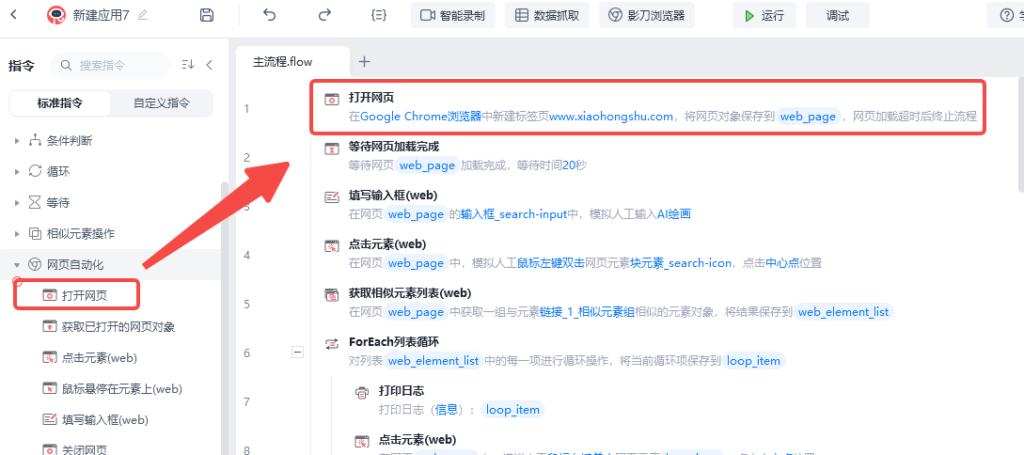
然后在配置框内,输入你要打开的网页(www.xiaohongshu.com),以及打开网页的浏览器类型,如chrome浏览器。
最后,它会把这个网页对象保存在一个web_page的变量里。(这里不用配置,可以改名)
然后你可以点击上面的运行按钮试试,RPA会自动帮我们用chrome浏览器打开小红书的网页。
2、等待网页加载完成。
打开小红书后,我们等待这个网页先加载完成,再去进行后面的操作。
即在指定的时间内,等待网页加载完成。

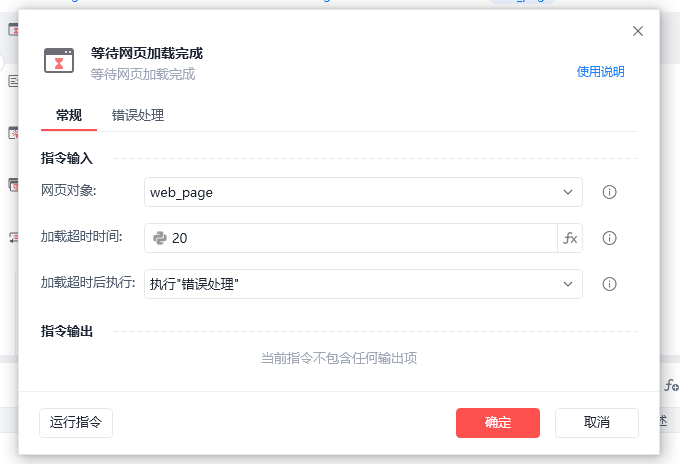
配置项如下:
- 网页对象:选择一个之前通过【打开网页】指令创建的网页对象。
- 加载超时时间:等待网页加载完成的超时时间,若指令执行报错”等待页面加载超时”可适当延长。
- 加载超时后执行:当等待时间超过加载超时时间后,执行【错误处理】或停止网页加载。
二、在输入框输入关键词并点击搜索
网页打开了后,我们需要在输入框输入要搜索的关键字,然后点击搜索。

这里我们可以分两步来做
1、填写输入框

首先我们要定位到操作目标,也就是网页的输入框。
我们点击去元素库选择,然后点击捕获新元素。
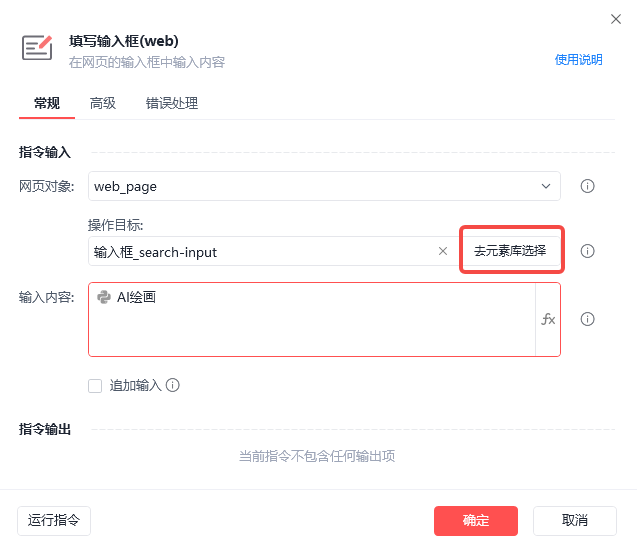
点击后,我们打开小红书网页,会看到鼠标移动到哪 ,哪里就会有一个红框,我们选择到输入框这里点击就可以。

操作目标这里就设置好了,然后在输入内容写上关键词,也就是你要搜索的内容。
2、点击元素
输入完成后,我们需要点击搜索按钮。
那么点击搜索按钮这个动作,我们可以用点击元素来实现。

这里其实和上面的填写输入框里的获取输入框对象的操作一样,我们用同样的方法,获取到搜索按钮即可。
那么到这一步,我们就成功的打开了小红书的网页,在输入框输入关键词,并且点击了搜索按钮。
接着,我们就需要获取到搜索后的笔记内容了。
三、循环依次点击每篇笔记,获取标题、内容、点赞数、收藏数和评论数
1、获取相似元素列表
要获取笔记内容,首先要点击进去具体的笔记。
小红书的笔记,我们都是需要点击封面图,然后再进入的。
那么我们就需要依次点击进去。
这里用获取相似元素列表的操作,也就是获取到小红书的封面图(封面图可以认为是相似的元素)

依旧还是在“去元素库选择”,然后点击捕获元素。获取相似元素列表这里的捕获元素的操作要注意一下,你需要点击多个封面图,RPA才会把他们作为相似的元素列表,并且自动帮你把所有的封面图都作为元素的列表。
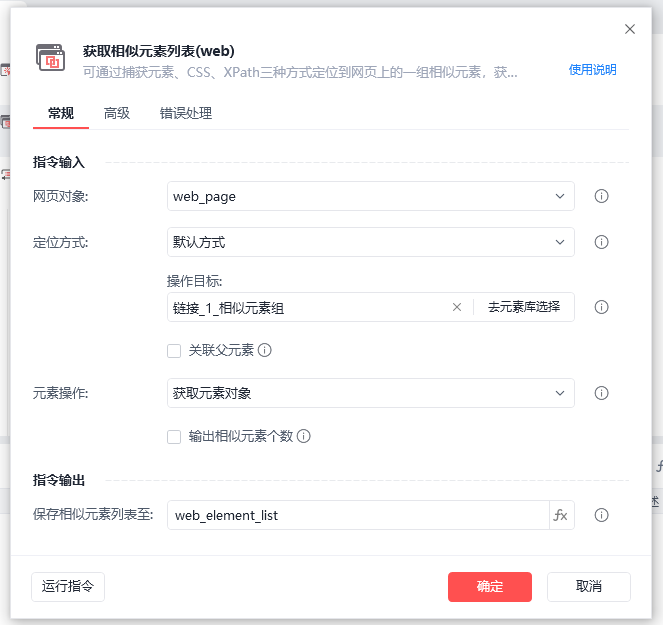
好了,获取到封面图列表后,相似的元素列表,就保存在了web_element_list这个变量里。
接着我们就要循环去点击web_element_list的所有封面图。(我们先不设置封面图的数量)
2、列表循环
加一个for each列表循环的操作

然后选择一个点击元素的操作,也就是点击封面图的意思。
接着可以设置一个等待,比如等待2秒,等待笔记内容加载完成(或许也不需要设置)

3、获取元素对象
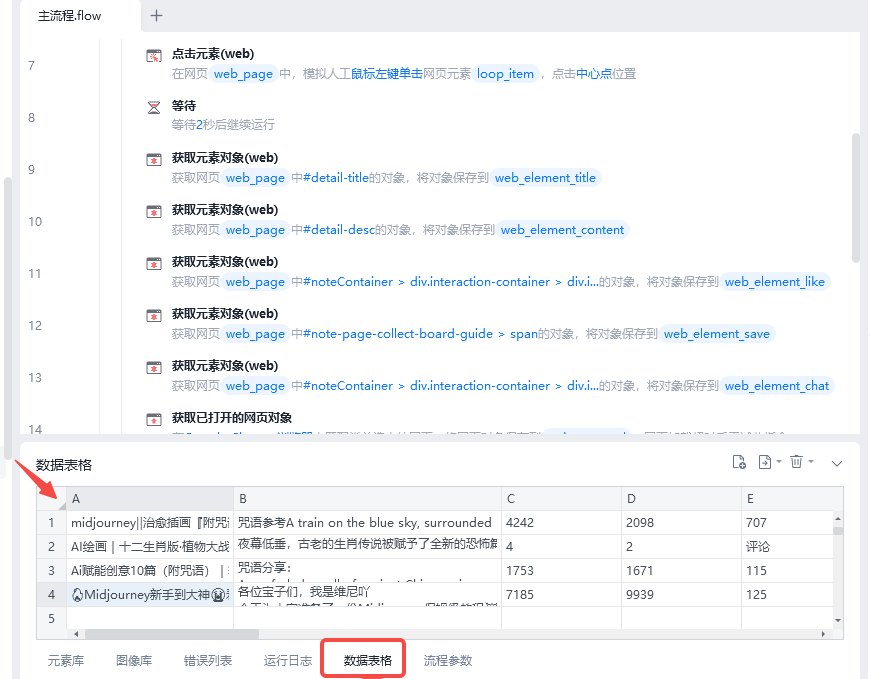
接着 ,我们就需要获取笔记内容了。这里,我们获取每个笔记的标题、正文、点赞数、收藏数、评论数、以及笔记的链接。
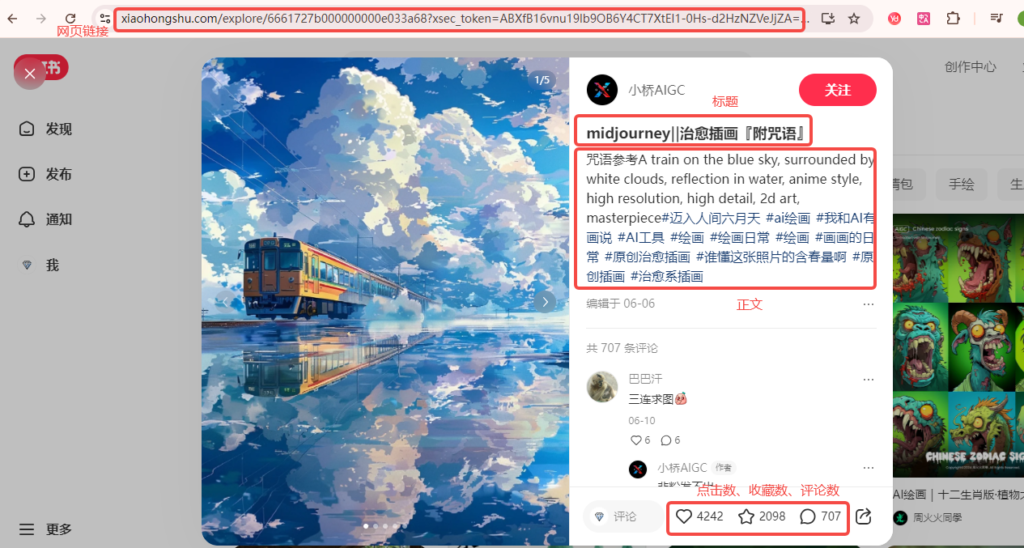
这里我们需要设置几个获取元素对象的操作,以及获取已打开的网页对象的操作,用途如下图:

我拿获取标题为例来说明下配置方法(其他的都是一样的操作)
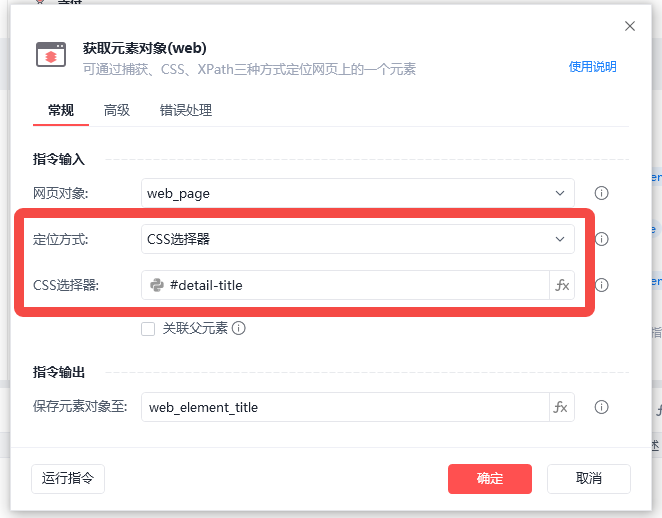
定位方式我们选择CSS选择器。
然后在CSS选择器这里,我们复制对应的元素名称。这个元素名称怎么获取?
我们在网页打开开发者工具,然后点击选择元素,再用鼠标点击标题位置,那么网页就会定位到这个元素。
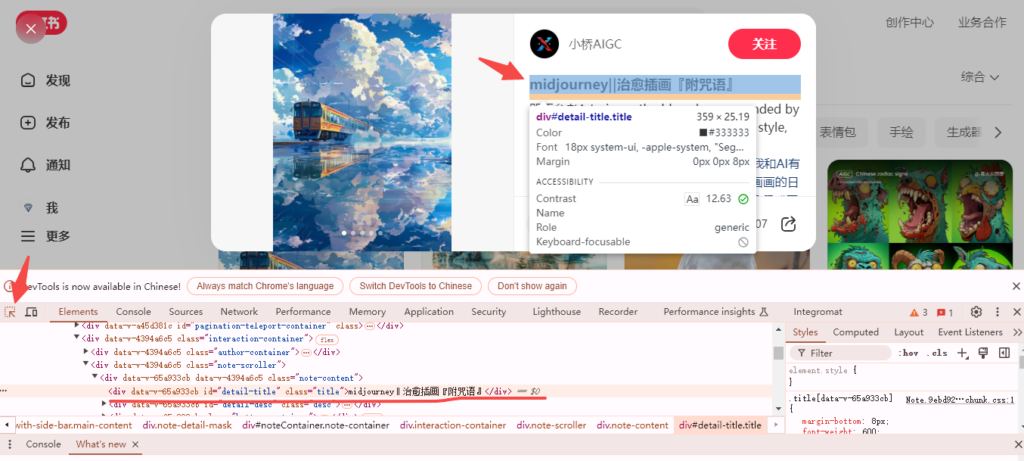
然后在这里点击鼠标右键,在弹出的菜单中选择“copy – copy selector”

然后你把copy下来的内容复制到RPA的CSS选择器里即可。 比如我们copy下来的标题的元素就是“detail-title”
这样就可以了。
然后我们用同样的方法,把笔记内容、点赞数、收藏数、评论数全都获取到。
4、获取已打开的网页对象
获取笔记的网址不需要这么麻烦。我们直接选择获取已打开的网页对象操作即可


四、将获取到的内容添加在表格中保存下来
元素都获取到了,最后我们需要把内容保存下来。
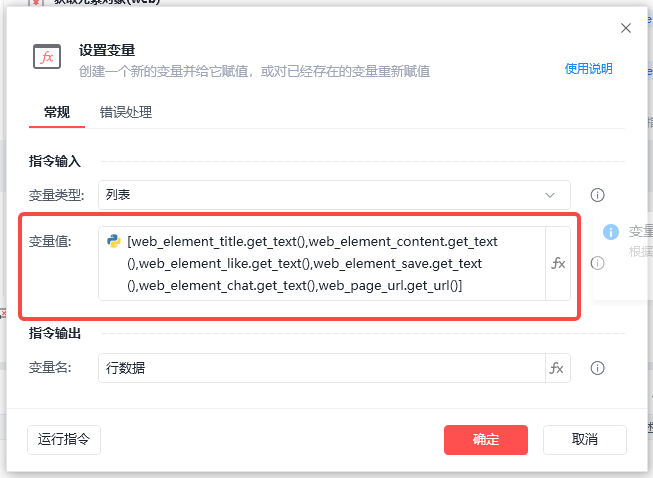
1、设置行数据
我们需要把笔记标题、笔记内容、点赞数、收藏数、评论数和笔记链接作为一行数据,按行添加到数据表格中。
我们设置一个变量,把行数据作为一个变量。

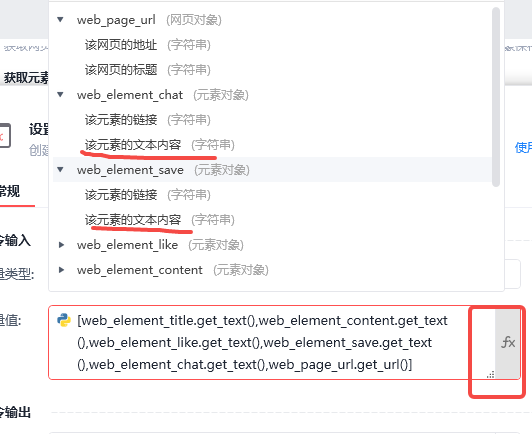
变量值,我们注意格式,是一个数组,[标题,内容,点赞数,收藏数,评论数,笔记链接],对应的每一个内容都选择对应对象的文本内容即可。
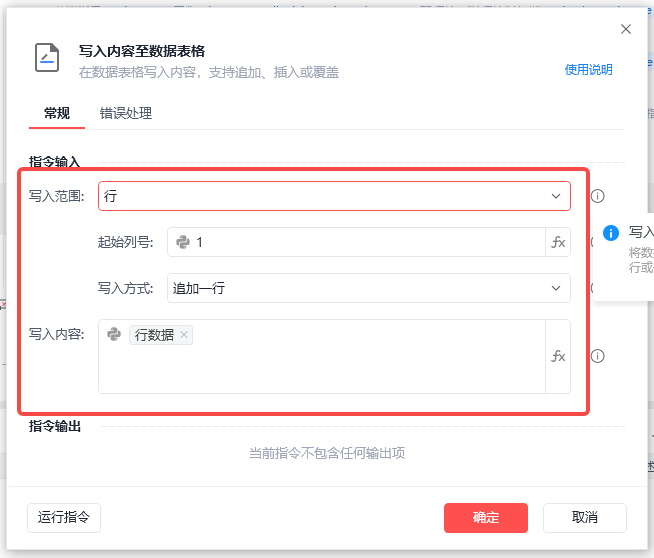
2、把行数据写入数据表格
最后,我们把行内容的变量,写入到数据表格中。

对了, 最后,不要忘记关闭掉笔记内容,这样,RPA才会继续循环去点击进入到第二个笔记内。
在小红书笔记这里,关闭按钮是在左上角。
那么用同样的方法,在RPA配置一个点击元素的操作即可。


那么到此,一个简单的小红书笔记内容获取的RPA流程,就做好了。
运行下试试看,我们在数据表格里就可以看到提取出来的小红书内容了~
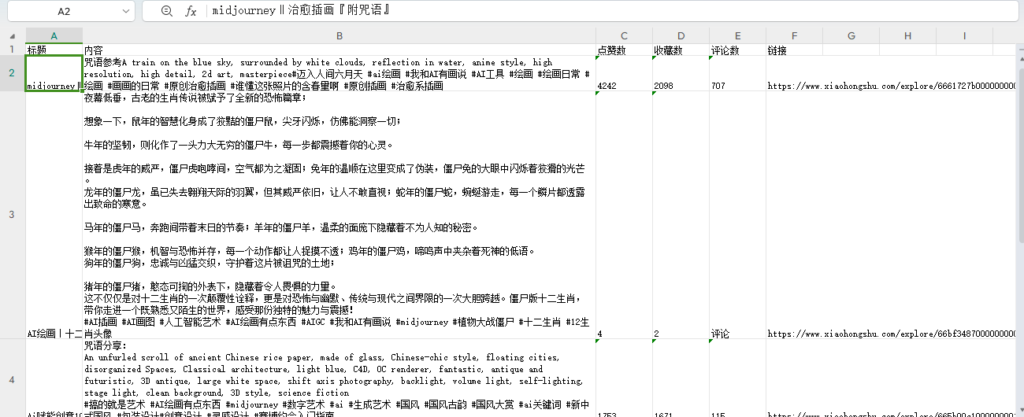
你也可以把表格内容下载下来

Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://accounts.binance.com/fr-AF/register-person?ref=JHQQKNKN
引人入胜的 旅游博客! 越来越棒!
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Yo, looking for a solid agent? Agent Bong88 seems like a good place to start. Check ’em out for yourself! agent bong88
Just grabbed the 669betbaixarapp. Installation was smooth, and the UI looks pretty slick! Fingers crossed for some good luck! Get yours here: 669betbaixarapp
Nếu bạn yêu thích các trò chơi bắn cá, ứng dụng 888SLOT sẽ không làm bạn thất vọng. Các game bắn cá tại đây được thiết kế với đồ họa đẹp mắt, hiệu ứng sống động và luật chơi đơn giản. TONY01-06S
Your article helped me a lot, is there any more related content? Thanks!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
betmgm Ohio online casino betmgm play betmgm Nevada
Feel action heartbeats in energy high. In ignation casino app, games win instant. Feel and flourish!
Venture reward plays exploratory and hills jackpot landscapes bonus through. In what is ignation, treasures to trek. Venture and vanquish!
Dive into the thrilling world of online gaming where endless fun awaits. Bovada Online Poker offers top table games and free spins for all players.
Big Bass Bonanza — fishing for fortunes! High volatility Bigger Bass Bonanza RTP meets rewarding free spins features.
Gates of Olympus doesn’t whisper — it roars. Zeus thunder + cascade chains = audio-visual overload and wallet overload. Experience gates of olympus big win at full volume.
Sweet dreams turn into reality! sugar rush slot real money packs tumbling wins, free spins and multipliers that go through the roof. Play today!
Spin starslot55 and watch the magic unfold. Expanding wild feature delivers respins and wins from either side. Low volatility, high hit rate — this is slot gaming at its finest.
stake app — where the biggest streamers play and the wins hit hardest. Fast crypto transactions, exclusive bonuses, and thousands of top-tier games. Level up your game today.
Step up your game at luckyland slots promo code 2026 today! Grab your signup bonus: 7,777 Gold Coins + 10 Sweeps Coins for free. Play, win, and redeem real cash prizes effortlessly!
DraftKings video poker Casino—your winning headquarters. Get 500 Cash Eruption spins after $5 bet + up to $1K back if needed. Level up!
betmgm new jersey Casino makes every player feel special. Sign up and receive up to $1,000 welcome match plus $25 free play. Win big with the best in the business.
Neplatte za znacku, platte za zdravi. Uspora az 80 %
https://opravdovalekarna.cz
La pharmacie en ligne qui respecte votre intimite. Ordonnances 100 % dematerialisees acceptees. Livraison rapide et fiable depuis 2019. MediPrivacy – sante sereine.Acheter acetaminophen
Join the millions delightful colossal on fanduel casino Virginia – the #1 natural money casino app in America.
Respite c start your $1000 TEASE IT AGAIN hand-out and deny b decrease every make up, хэнд and rotate into real readies rewards.
Fast payouts, whopping jackpots, and continuous fight – download FanDuel Casino any longer and start playing like a pro today!
FanDuel Casino is America’s #1 online casino, delivering unhesitating thrills with play ignition casino , restricted slots like Huff N’ Word, and live dealer act normal at your fingertips. Hip players get 500 Extra Spins supplementary $40 in Casino Tip just in return depositing $10—added up to $1,000 dorsum behind on first-day closing losses. Calling all Thrillionaires: accompany now, operate your nature, and turn every blink into epic wins!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://www.binance.com/ru/register?ref=O9XES6KU
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Torne-se VIP do Betano desde o primeiro dia. Desbloqueie até €500 de bônus de boas-vindas https://betanogame.org/pt/ e aproveite jogos exclusivos de cassino ao vivo. Ganhe muito e saque rápido.