如何通过n8n来定期推送Google trends里的趋势关键词?帮你定期了解某地区某时间段内的热门关键词。
我们用n8n和飞书多维表格来尝试下。
当每次运行n8n的流程
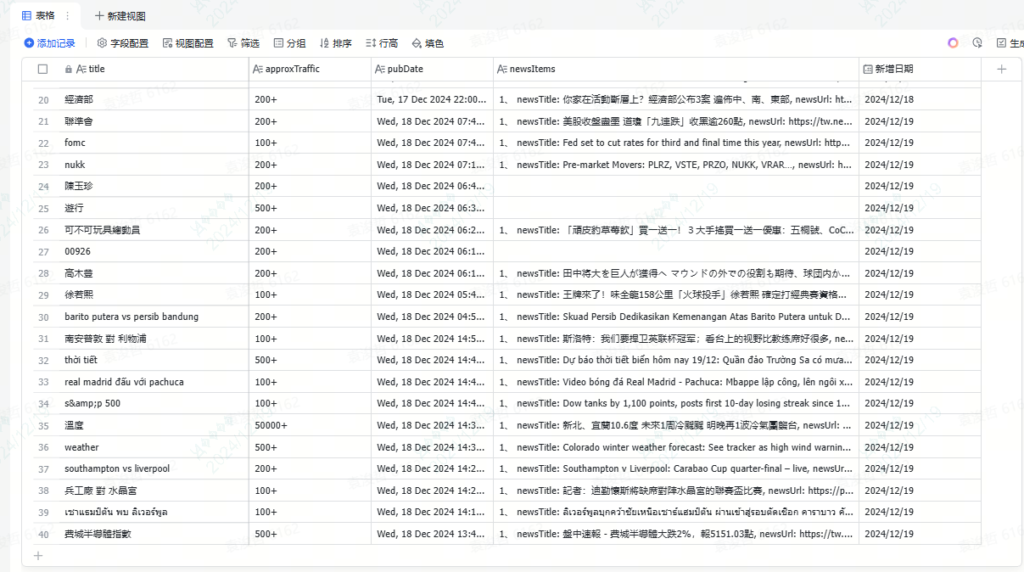
就会自动在飞书多维表格里新增过去某段时间内的关键词、搜索量、发布时间和对应的新闻。
好的,今天我们就来讲讲如何来实现。
一、Google trends
Google trends 是没有对外开放的API的,所以想通过接口来获取数据目前是不行的。
但是发现它有对应的rss可以用
我们在Google trends的时下流行菜单下,在筛选框选中地区、时间等,然后点击导出,在导出的下拉框内,有一个“RSS feed”
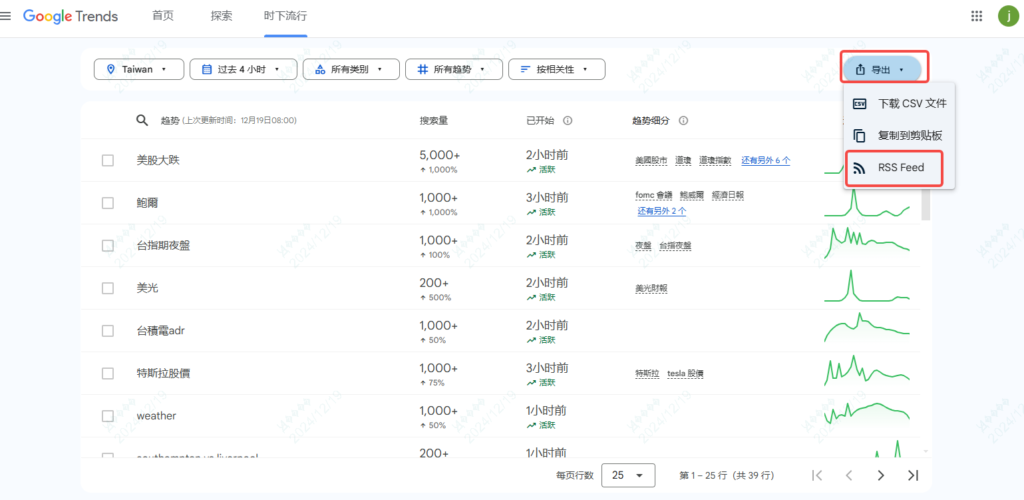
我们点击进去,看到这样一个页面,这个就是rss的数据源,我们可以通过这个rss来获取数据。

简单看一下这个rss,发现它有这些数据内容:
{
"title": "关键词",
"approxTraffic": "搜索量",
"pubDate": "发布时间",
"newsItems": [
{
"newsTitle": "新闻标题",
"newsUrl": "新闻链接",
"newsSource": "新闻来源"
},
{
"newsTitle": "新闻标题",
"newsUrl": "新闻链接",
"newsSource": "新闻来源"
},
{
"newsTitle": "新闻标题",
"newsUrl": "新闻链接",
"newsSource": "新闻来源"
}
]
}我们可以用n8n自动化工具把这些内容提取出来并定期推送给我们。
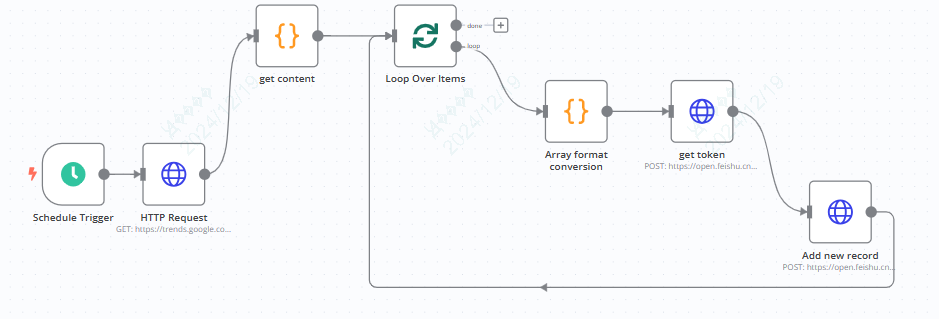
二、n8n
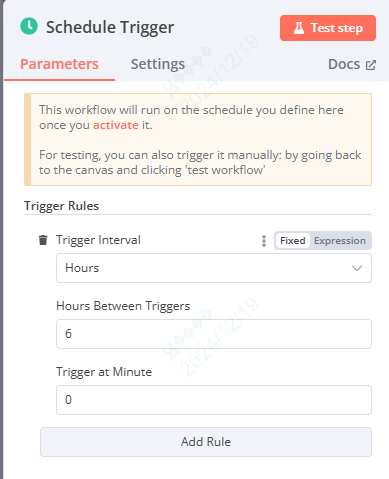
1、Schedule Trigger
首先在开始节点,定义流程触发的时间和频率

比如我们定义每6小时触发一次这个工作流
2、http节点-获取rss内容
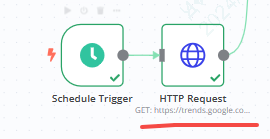
我们通过http的节点来获取rss链接中的内容

method为get
URL为https://trends.google.com/trending/rss?geo=TW
其他内容无需配置
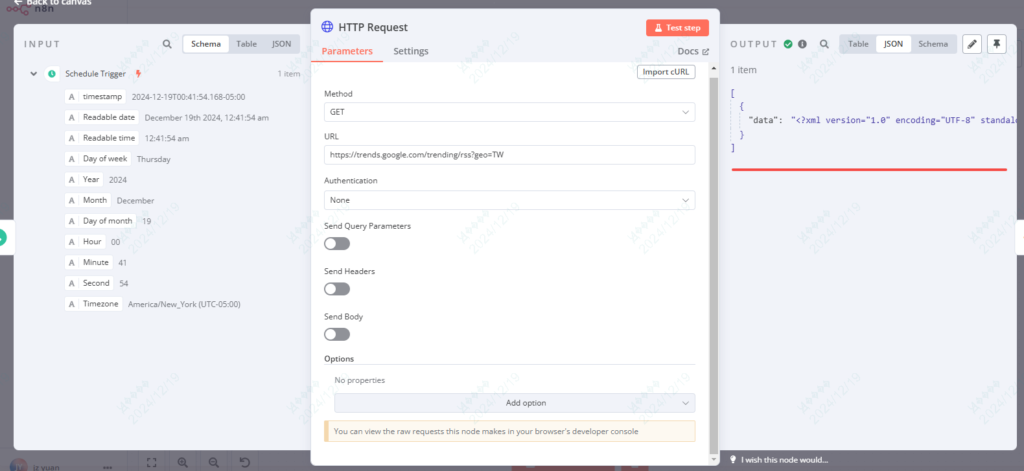
点击test step试着运行一下,也会正常的输出内容。
3、code节点-提取rss里所需内容
因为从http节点输出的内容,格式是一大串字符,我们还是需要对它加工一下,变的结构化一点。
所以我们用code节点,写个js,用正则表达式来提取和定义其中的字段内容
// 获取 XML 数据
const xmlData = items[0].json.data; // 获取 RSS XML 内容
// 定义正则表达式来提取 item 内容
const itemRegex = /<item>(.*?)<\/item>/gs;
const titleRegex = /<title>(.*?)<\/title>/;
const approxTrafficRegex = /<ht:approx_traffic>(.*?)<\/ht:approx_traffic>/;
const pubDateRegex = /<pubDate>(.*?)<\/pubDate>/;
// 定义新闻项正则表达式
const newsItemRegex = /<ht:news_item>(.*?)<\/ht:news_item>/gs;
const newsTitleRegex = /<ht:news_item_title>(.*?)<\/ht:news_item_title>/;
const newsUrlRegex = /<ht:news_item_url>(.*?)<\/ht:news_item_url>/;
const newsSourceRegex = /<ht:news_item_source>(.*?)<\/ht:news_item_source>/;
// 存储最终提取的数据
const results = [];
// 匹配所有的 <item> 标签
let itemMatch;
while ((itemMatch = itemRegex.exec(xmlData)) !== null) {
const itemContent = itemMatch[1];
// 提取 <title>、<ht:approx_traffic> 和 <pubDate>
const title = (itemContent.match(titleRegex) || [])[1] || '';
const approxTraffic = (itemContent.match(approxTrafficRegex) || [])[1] || '';
const pubDate = (itemContent.match(pubDateRegex) || [])[1] || '';
// 提取所有的 ht:news_item
const newsItems = [];
let newsItemMatch;
while ((newsItemMatch = newsItemRegex.exec(itemContent)) !== null) {
const newsItemContent = newsItemMatch[1];
const newsTitle = (newsItemContent.match(newsTitleRegex) || [])[1] || '';
const newsUrl = (newsItemContent.match(newsUrlRegex) || [])[1] || '';
const newsSource = (newsItemContent.match(newsSourceRegex) || [])[1] || '';
newsItems.push({
newsTitle,
newsUrl,
newsSource
});
}
// 存储提取的数据
results.push({
title,
approxTraffic,
pubDate,
newsItems
});
}
return results;通过加工处理,对应的内容就变的比较结构化,如下图,清晰很多。

4、循环节点
好了,那么我们要把数组里的所有内容都依次添加到飞书的多维表格内,所以就需要遍历数组里的内容。
我们在n8n添加一个循环节点
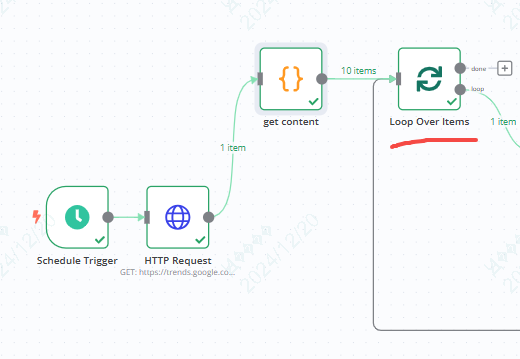
5、code节点- 转换数组格式
因为我们要把title、approxTraffic、pubDate和newsItems分别作为4列添加到对应的多维表格内,title、approxTraffic、pubDate这三个字段都是比较标准的,但是newsItems就比较特殊,它是一个数组的格式
"newsItems":
[
{
"newsTitle":
"柯文哲聲請交付周榆修請辭民眾黨主席聲明 北院裁准",
"newsUrl":
"https://tw.news.yahoo.com/%E6%9F%AF%E6%96%87%E5%93%B2%E8%81%B2%E8%AB%8B%E4%BA%A4%E4%BB%98%E5%91%A8%E6%A6%86%E4%BF%AE%E8%AB%8B%E8%BE%AD%E6%B0%91%E7%9C%BE%E9%BB%A8%E4%B8%BB%E5%B8%AD%E8%81%B2%E6%98%8E-%E5%8C%97%E9%99%A2%E8%A3%81%E5%87%86-022758897.html",
"newsSource":
"奇摩新聞"
},
{
"newsTitle":
"起訴前震撼彈!法官裁准柯文哲寄「黨主席辭職信」給周榆修",
"newsUrl":
"https://udn.com/news/story/124199/8438036",
"newsSource":
"聯合新聞網"
},
{
"newsTitle":
"柯文哲確定辭民眾黨主席!書面表交付辭職聲明 法院裁准",
"newsUrl":
"https://www.chinatimes.com/realtimenews/20241220001856-260402",
"newsSource":
"中時新聞網"
}
]我们希望把它变成一个多行文本,直接放在多维表格的单元格里。类似下面这样一个格式
1、 newsTitle: 柯文哲聲請交付周榆修請辭民眾黨主席聲明 北院裁准, newsUrl: https://tw.news.yahoo.com/%E6%9F%AF%E6%96%87%E5%93%B2%E8%81%B2%E8%AB%8B%E4%BA%A4%E4%BB%98%E5%91%A8%E6%A6%86%E4%BF%AE%E8%AB%8B%E8%BE%AD%E6%B0%91%E7%9C%BE%E9%BB%A8%E4%B8%BB%E5%B8%AD%E8%81%B2%E6%98%8E-%E5%8C%97%E9%99%A2%E8%A3%81%E5%87%86-022758897.html, newsSource: 奇摩新聞
2、 newsTitle: 起訴前震撼彈!法官裁准柯文哲寄「黨主席辭職信」給周榆修, newsUrl: https://udn.com/news/story/124199/8438036, newsSource: 聯合新聞網
3、 newsTitle: 柯文哲確定辭民眾黨主席!書面表交付辭職聲明 法院裁准, newsUrl: https://www.chinatimes.com/realtimenews/20241220001856-260402, newsSource: 中時新聞網所以,这一步也涉及到对”newsItems”字段格式的一些调整和转化
添加一个code节点

// 获取传入的 newsItems 数组
const newsItems = items[0].json.newsItems;
// 生成最终字符串格式
let result = '';
newsItems.forEach((newsItem, index) => {
// 逐项构造 newsItems 格式
result += `${index + 1}、 newsTitle: ${newsItem.newsTitle.replace(/"/g, '\\"')}, newsUrl: ${newsItem.newsUrl.replace(/"/g, '\\"')}, newsSource: ${newsItem.newsSource.replace(/"/g, '\\"')}`
});
;
// 输出结果
return [
{
json: {
formattedNewsItems: result
}
}
];
这样就可以转换为我们需要的格式
6、连接飞书多维表格
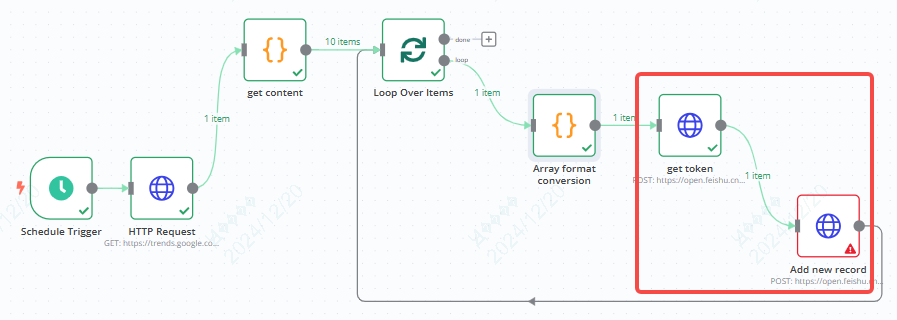
通过两个http节点来实现,一个是获取token,一个是新增记录
关于如何连接飞书多维表格,在之前的一篇文章已经有详细介绍,可以直接看。
同步reddit帖子内容到飞书多维表格 | n8n X 飞书
链接上之后,运行流程,就可以把rss的内容定时同步到飞书多维表格内

然后我们就可以在多维表格里,去利用多维表格的能力来做一些配置。
比如可以当多维表格新增记录后,通过飞书来推送一些信息给我们。
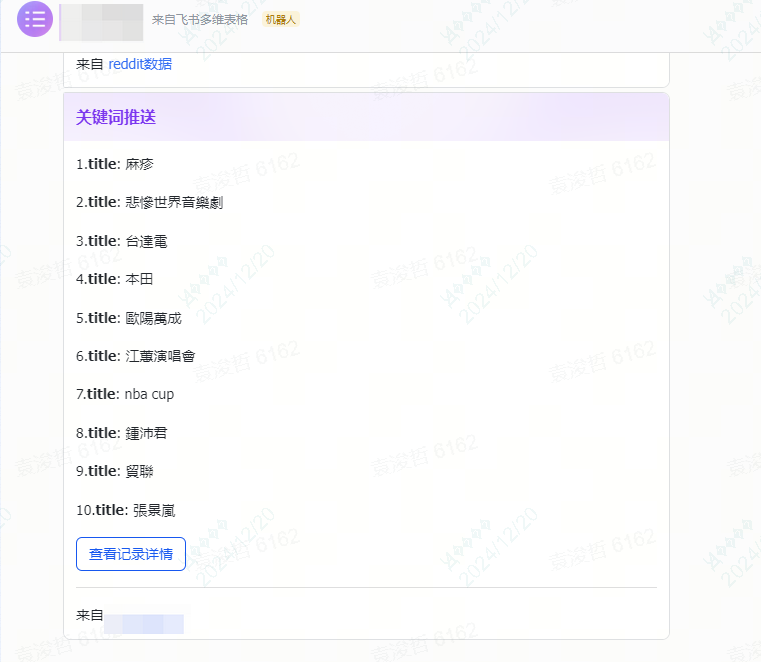
通过自动化流程,大大提升了我们获取信息的效率,^_^