
有时候,我们可能会需要把固定格式的发票里的一些内容提取出来,然后记录到表格里。
比如这个发票:

举例可能我需要把发票代码、开票日期、纳税人识别号和合计金额提出来并录入到表格里。
如果用人工的话,这种重复工作,费时费力。
所以有没有一些自动化的方法来帮我们实现?
今天我们试下用n8n,来完成这个工作。
需要实现的效果:我们只需要在google drive上传我们的发票pdf,然后工作流会自动提取出所需要的字段,并且自动写入到google sheets里。(我们所需要做的工作只是上传发票到google drive即可,剩余的工作都由自动化流程帮我们处理)


这样对我们来说就会非常的方便。
那么接下来我们具体看看如何实现。
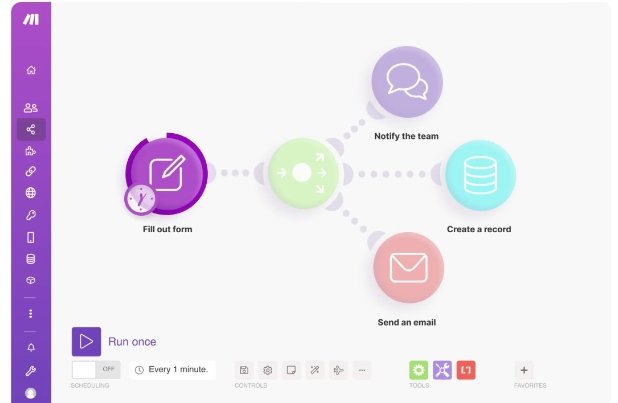
这是一个完整的流程图

先说说思路,这里主要分成四个大的步骤

一、主要是实现当流程检测到google drive有上传文件时,即自动触发此工作流,然后将我上传的文件做一个download的操作。
二、这里主要是用LlamaParse的模型,来帮我们解析发票附件,然后把发票的内容转化为文本输出。
三、将发票的文本数据,提取出我们所需要的字段及对应的内容。
四、将字段内容写入到对应的google sheet里。
那么接下来我们每个步骤详细看看节点是如何配置的。
前期准备:
在google drive新建文件夹,可以命名为发票,然后在这个文件夹可以先上传一张pdf的发票文件,用作后续测试。

一、检测google drive上传文件并且做download的操作
1、Google Drive Trigger

开始节点,我们配置一个Google Drive Trigger节点,然后在配置界面里,配置相关信息

(1)Credential to connect with:这里需要连接上我们的google drive账户,通过OAuth2 API的方式,需要我们输入对应的Client ID和Client Secret。
(2)Poll Times:触发的时间或频率。我们可以在下拉列表中选择需要的时间。

(3)Trigger On
触发的条件,是具体的某个文件发生变化就触发流程,还是说某个文件夹里有变化就触发流程。
这里我们选择某个文件夹里有变化就触发流程,即Changes Involving a Specific Folder

(4)Folder
Trigger On选择了某个文件夹里有变化就触发流程,那么我们就需要选择是哪个文件夹了。
这里可以选择到我们google drive里所有的文件夹,比如我们把发票附件存放在“发票”这个文件夹里,那么这里我们就选择“发票”文件夹。

(5)Watch For
监控变动的类型,我们选择File Created,也就是当文件夹里有新增文件的操作时,才会触发流程。

那么这个节点的基础配置就完成了。
我们可以在google drive文件夹里上传一个pdf发票附件,然后点击右上角的“Fetch Test Event”来测试一下。
看到output是正常输出数据了,说明这个节点是没有问题的。

2、Google Drive – download file

第二个节点,我们配置一个Google Drive节点,选择download file的操作。意思就是我们需要把监控到的文件download一下(不是download到本地),后续要传给模型做解析。
这里的配置方法如下:

(1)Credential to connect with:同第一个节点,连接账户,第一个节点配置完成后,这个节点直接选择即可,不需要重复配置。
(2)Resource:选择file,即针对file进行操作
(3)Operation:选择download的操作
(4)File:要选择我们download的对象,这个对象是一个变量,我们选择by id,然后把第一步output出来的文件的id,拖拽到中间的空格即可。

(5)Binary Property:输入data即可。
然后我们执行一下节点试试看。
output里就正常输出了这个文件的数据。

二、用LlamaParse模型,来解析发票附件
也就是流程里的这一块内容。

因为LlamaParse在n8n里没有现成的节点可用,所以我们需要用HTTP Request节点来实现。(调用LlamaParse的API)
这里的节点我们依次解释下。
前置工作:首先我们需要注册下LlamaParse,获取到它的API key。
进入这个网站https://cloud.llamaIndex.ai注册一个免费帐户,然后免费获得API密钥。(每天允许上传1000次)

这个API key记下来,后续我们在n8n中调用LlamaParse API时会使用。
LlamaParse的接口文档:https://docs.cloud.llamaindex.ai/ 可以选择自己需要的接口。
1、将PDF上传到LlamaParse服务

首先我们需要把第二步download下来的pdf文件,上传到LlamaParse服务里。
这里用到https://api.cloud.llamaindex.ai//api/v1/parsing/upload的接口。
在HTTP Request节点节点我们做如下配置:
(1)基础信息:

method选择post,url复制我们的接口地址
认证这里,我们选择Generic Credential Type,Header Auth,然后在Credential for Header Auth这里,添加account,并且输入我们的API key进行连接即可。

(2)Headers
配置一个参数,name:Content-Type ,value:multipart/form-data

(3)Body

Body Content Type选择Form-Data,Parameter Type选择n8n Binary Data
然后name为file,Input Data Field Name为data。
2、查询PDF处理作业状态

查询PDF处理作业状态的API调用。
在这里,我们使用HTTP Request节点、再加一个SWITCH节点(监控状态,确定作业是否完成)和一个WAIT节点(用于限制调用以保持在API服务速率限制之内)实现了这个流。
(1)HTTP Request节点

method选择get方法。
url用查询状态的接口,https://api.cloud.llamaindex.ai//api/v1/parsing/job/{{ $json.id }}。 注意,{{ $json.id }}是一个变量,即此任务的job的id,同样也是把之前节点output的job id拖拽到里拼起来即可。
认证这里和之前的节点一样。
其他不需要单独的配置。
(2)SWITCH节点
SWITCH节点,主要用来监控job的状态,确定作业是否完成

这里我们可以根据作业的status即状态,来配置接下来的节点走向。
如状态为错误即结束,状态为成功即进入到下一个http节点,状态为进行中,就到wait节点进行等待。
(3)WAIT节点
wait节点我们设置一个等待时间即可

3、获取PDF的解析输出
当工作任务的状态为成功时,即调用接口成功,则会进入到解析的节点。

同样的这里我们只需要配置接口地址即可。

method选择get,url输入接口地址,https://api.cloud.llamaindex.ai//api/v1/parsing/job/{{ $json.id }}/result/raw/markdown,注意{{ $json.id }}也是动态变量,即这条任务的job的id
那么到这里,解析PDF的配置就完成了,可以运行下流程试试看
看到output这里,就已经把pdf发票的内容,都解析成文本变成一个data数组了。

那么接下来的工作,我们就需要从里面获取我们关心的字段内容了。
我们以获取”发票代码”、”开票日期”、”纳税人识别号”和”合计”这四个字段来举例说明。
三、将发票的文本数据,提取出我们所需要的字段及对应的内容。
因为发票的格式基本都是固定的,我们添加一个code节点,用js的方式来去获取到对应的字段内容。

用正则表达式获取对应的字段内容,执行后,则会把所需的四个字段output出来。

// 获取 HTTP Request 节点的输出
const inputData = items[0].json.data;
// 使用正则表达式提取字段
const invoiceCodeMatch = inputData.match(/发票代码\|([^\|]+)/);
const issueDateMatch = inputData.match(/开票日期\|([^\|]+)/);
const taxNumberMatch = inputData.match(/纳税人识别号:([^\s]+)/);
const totalAmountMatch = inputData.match(/合\s+计:\s+¥([\d\.]+)/);
const invoiceCode = invoiceCodeMatch ? invoiceCodeMatch[1] : '';
const issueDate = issueDateMatch ? issueDateMatch[1] : '';
const taxNumber = taxNumberMatch ? taxNumberMatch[1] : '';
const totalAmount = totalAmountMatch ? totalAmountMatch[1] : '';
return [{
json: {
invoiceCode,
issueDate,
taxNumber,
totalAmount
}
}];四、将字段内容写入到对应的google sheet里。
好了,那么就到最后一个字段了,获取到了字段,我们需要把字段的信息添加到google sheet里
首先我们在google sheet里新建一个表格,为表格命名,并且添加上列字段

然后我们在google sheet节点里,把上一步output出来的字段和sheet里添加的字段对应起来。
此节点需要配置下面一些内容


1、Credential to connect with:这里需要连接上google sheet账户,连接方式和google drive的操作方法是一样的。
2、Resource:选择Sheet Within Document。
3、Operation:选择Append Row,即添加行。
4、Document和sheet:需要选择你刚才新建的表格的名称,即对应的工作表sheet页。
5、Mapping Column Mode:选择Map Each Column Manually,即对应列进行添加。
6、Values to Send:这里就需要把字段变量和sheet里的列对应起来了。
我们直接把字段变量,拖拽到对应的输入框即可。字段变量要和sheet里的字段列一一对应上。

好了,那么到此,这个流程就基本上配置完成了。

你可以点击执行来试试看。
执行后,可以看到sheet里就会自动生成一行数据了。

最后,记得保存并且打开工作流,这样,当你在google drive上传发票pdf后,就会自动在google sheet里生成一行数据。非常的方便。


Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Been having some fun with jjwinbet lately. It seems like a really trust worthy site, I can’t complain! jjwinbet
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Sau khi cài đặt ứng dụng, mở ứng dụng và chọn “Đăng ký”. slot365 link Bạn nên đủ các thông tin yêu cầu bao gồm tên đăng nhập, mật khẩu, địa chỉ email và số điện thoại khi bạn thực hiện đăng ký tài khoản mới. Thông tin chính xác thì quá trình xác minh tài khoản diễn ra thuận lợi. TONY12-26
So, I stumbled on 678bet. It’s alright haha. I was a bit wary, but it seems legit enough for a little risk. The games seem kinda fair and worth risking the cash. Go check it out: 678bet.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://accounts.binance.info/da-DK/register-person?ref=V3MG69RO
Your article helped me a lot, is there any more related content? Thanks!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.