
需求:在日常工作中,会有一个场景,我会提供一个固定文件模板给大家填写内容,填写完成后我会把这些文件都上传到google drive,然后自动帮我把文件名改成我需要的格式
举个例子,比如我有一些人员的简历,这些简历都是固定的格式

那么我希望把这些简历上传到google drive后,系统自动帮我把文件名改成“{简历姓名}的简历.pdf”
比如 Penny王的简历.pdf
那么我希望通过make自动化来实现这个需求。
具体应该怎么做呢?
大概需要这么几个步骤
1、监控google drive文件夹是否有新增文件
2、如果有新增文件,就做download操作
3、用pdf.co解析download下来的文件,把里面的文字提取出来
4、去解析并提取所需要的字段信息,并保存成变量
5、修改google drive里对应的文件名称
那么接下来我们按步骤来看具体如何配置
1、监控google drive文件夹是否有新增文件
在开始节点,我们选择Google drive,然后选择 watch files in a folder的操作。目的就是去监控我们文件夹里的文件变化
比如我有一个“简历”的文件夹,那么这个节点就是去监控这个文件夹里文件的变化
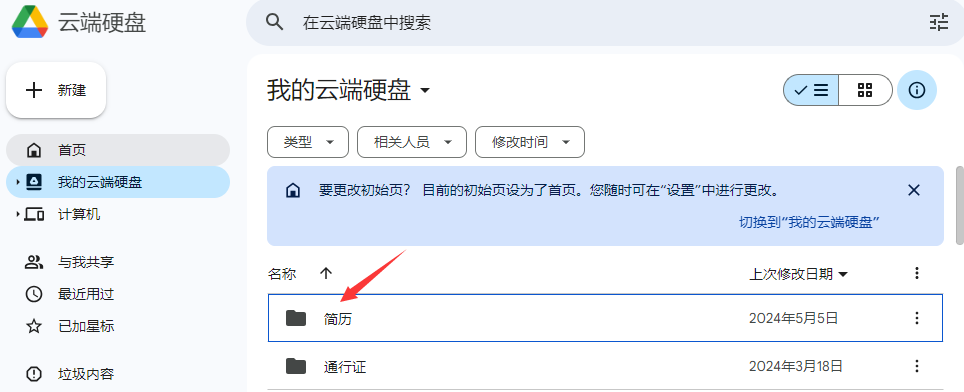
配置项这里,首先我们连接到自己的Google drive,然后选择到“简历”这个文件夹。
2、如果有新增文件,就做download操作
这一步主要是为了把文件download给pdf.co做解析,所以需要有一个download的操作
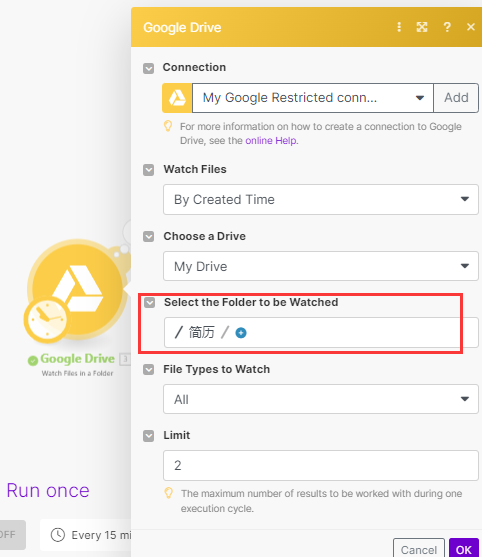
我们新增一个Google drive节点,选择 download a file的操作
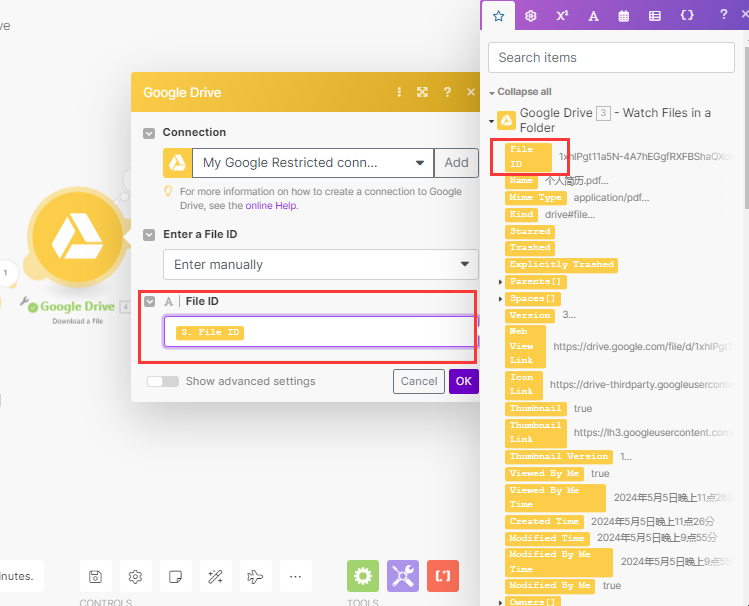
在配置项里,点击file id 的输入框,然后选择file id字段,也就是上一步获取到的file id
这两个节点配置完成后,你可以在google drive上传一个文件,然后运行流程试试看效果
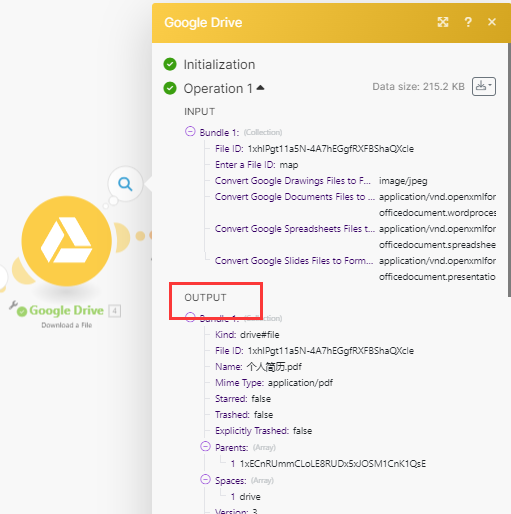
如上图,会看到download这里已经成功的output出了上传的文件
3、用pdf.co解析download下来的文件,把里面的文字提取出来
用pdf.co的节点,选择convert from pdf操作

注:用这个节点前,要去pdf.co的官网完成注册,然后获取到api key。pdf.co不是完全免费的,但是他的免费额度还是蛮高的
连接上pdf.co后,如下,这几个配置项注意一下
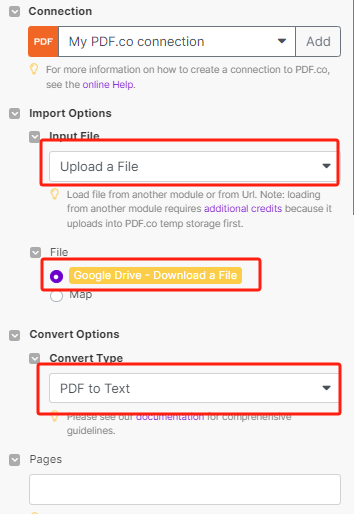
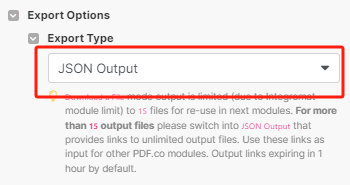
简单来说这个节点的目的就是把google drive的文件download下来,然后upload到pdf.co里,让pdf.co进行解析,最后把解析完成的结果用json格式output出来。
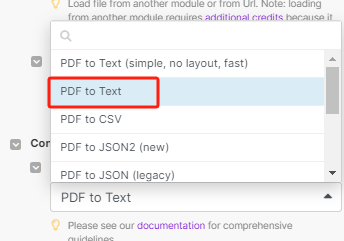
这里要注意的一点是,convert type 要选择 pdf to text
运行后输出的样式如下:
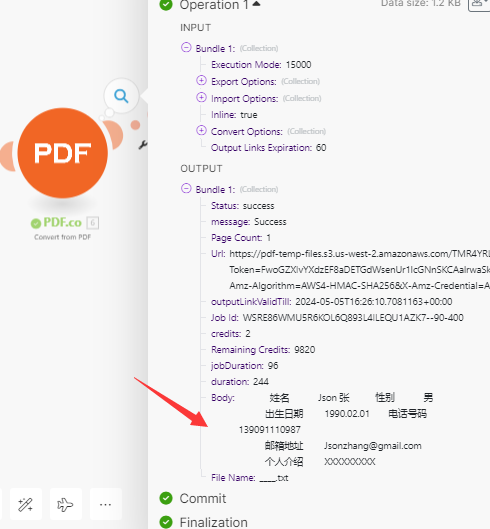
保留了pdf文件的排版,也提取出的文字。
接下来的思路,我们要从文本中提取出我们需要的内容,然后转为一个变量。因为格式比较固定,所以可以用正则表达式来提取。
4、去解析并提取所需要的字段信息,并保存成变量

这里我们用两个节点实现
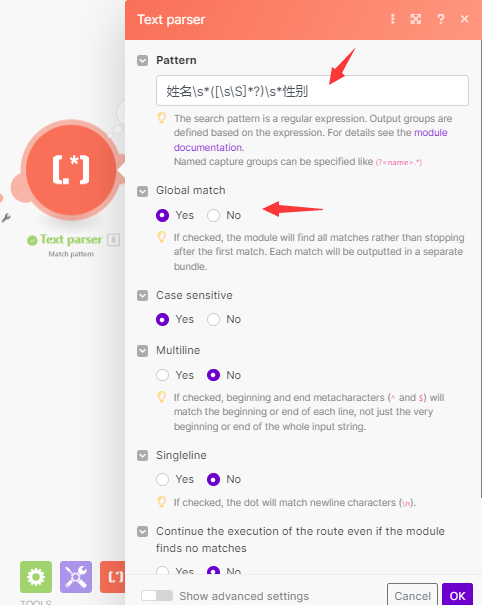
(1)text parser,操作为match pattern
需要配置如下选项:
- pattern:输入正则表达式“姓名\s([\s\S]?)\s*性别”,这个表达式的意思就是获取姓名和性别之间的文字,并去掉空格。
- Global match选择yes
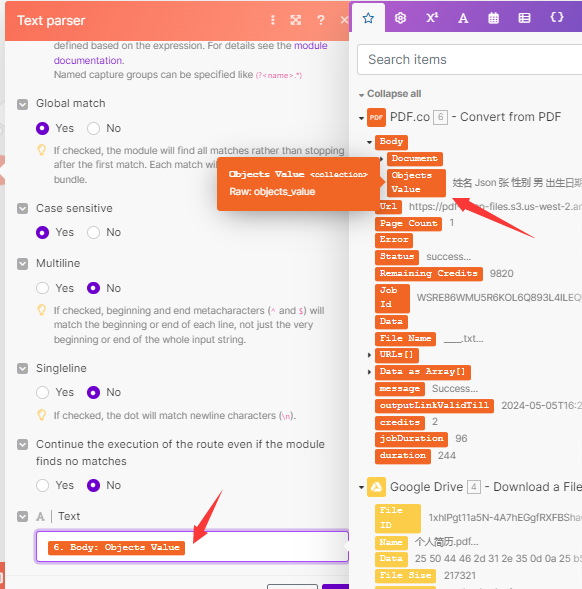
- text选择pdf解析出来的objects value
(2)设置变量
- 变量名称按需配置
- value选择上一步提取出来的姓名
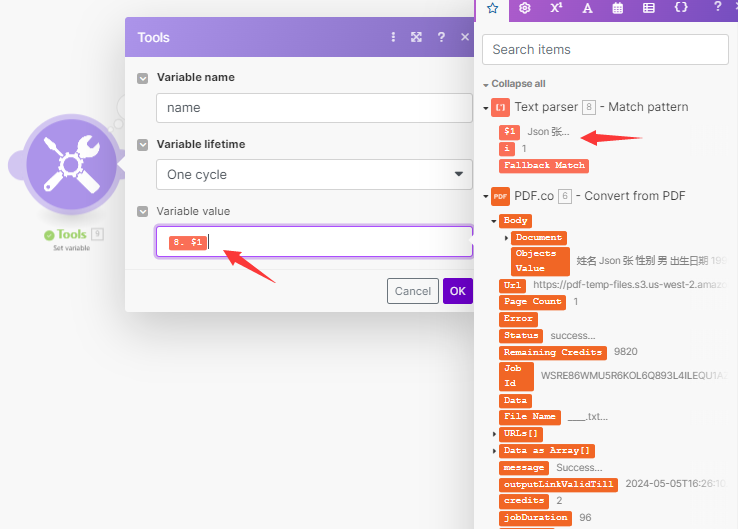
到此,pdf里的姓名就提取出来了
5、修改google drive里对应的文件名称
最后一个节点,添加Google drive ,选择update a file操作
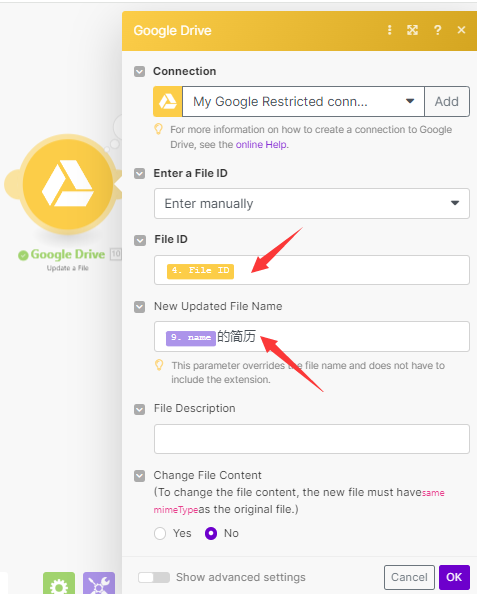
File id那里,选择我们一开始第二节点upload file的file id字段
File name ,我们把之前每个环节设置的变量拼起来即可,因为我们只需要name这个变量,所以就选择上一步的name变量,然后加上“的简历”的固定文本。
到此,我们的流程就配置完成了,每当在google drive上传文件并运行流程后,文件都会按照提取出来的name+的简历这样的格式修改文件名
比如这样

最后,你可以设置一下流程的运行频率
在第一个节点,点击时间图标,在里面配置流程运行的频率,比如15min,这样每15min,流程就会自动执行一次。

当然,这个流程只是一个比较简单的,以此类推,如果有同样的上传文件并修改文件名称的需求,都可以按照这个思路来完成。

I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Những điểm ấn tượng chỉ có tại nhà cái 888slot com TONY12-10A
Betvnapp is pretty convenient if you’re betting on the go. The app is smooth, and it’s easy to find what you’re looking for. Give it a try if you’re into mobile betting. Download here: betvnapp
Sup gamblers! Heard about qqlivebet for live betting action. Anyone tried placing bets there? Good odds or what?
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://www.binance.info/el/register?ref=DB40ITMB
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.info/register-person?ref=IHJUI7TF
Your article helped me a lot, is there any more related content? Thanks!
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
slot365 là gì sử dụng máy chủ AWS – đảm bảo tốc độ tải game ổn định, không lag dù cao điểm. Trải nghiệm mượt mà như đang chơi offline! TONY02-11O
Your article helped me a lot, is there any more related content? Thanks! https://www.binance.info/register?ref=IHJUI7TF
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Lựa chọn xn88 là lựa chọn một nền tảng giải trí có trách nhiệm. Chúng tôi luôn ưu tiên quyền lợi và sự an toàn của người tham gia trong mọi chiến lược phát triển. (Tương tự cho đến đoạn 20, tập trung vào: Sự tín nhiệm, đẳng cấp quốc tế, tính minh bạch) TONY03-11O