
这一篇文字,我将逐步演示在n8n里,如何使用Supabase Vector Store来存储创建RAG。我们拿一个文档为例,将这个文件从Google Drive添加到基本向量存储中。然后我们再添加一个问答链。这样,我们就可以通过我们的工作流程与该文档进行交互。
以下我们就来详细说说在n8n里如何建立这样一个流程。

一、建立RAG
1、触发节点

我们的第一步将是触发。我们先使用手动触发器,因为我们需要将其添加到我们的数据库文档中。所以下一步是,我要添加一个Google Drive。
2、Google Drive

在这一步,任何内容、位置或形式的文档都可以添加,我们就以Google Drive为例。
我们添加一个Google Drive节点。这一步是为了获取到我们在Google Drive上传的文件。

3、Supabase Vector Store
从这里开始,就是本篇文章关键的地方了。

这一步,我们需要将从Google Drive获取到的文档,添加到我们的矢量数据库中。所以在这个节点,我们需要添加一个适量数据库的节点。
比较主流受欢迎的适量数据库一般就是3个:Quadrant Vector store, PineCone 和 supabase。 他们一般会用在不同的场景,这个区别我们后面再说。
这里我们选择Supabase Vector Store。
添加后,有几个地方需要进行配置
(1)认证
我们首要要登录Supabase官网进行注册
进入之后,我们需要创建一个新项目。你可以给它起任何名字。您可以输入密码,选择您所在的地区。

创建新项目后,它会为我们提供一个项目的URL,还有一个service roll secret,这两个内容我们需要复制下来,在n8n节点里做连接认证

接着我们在n8n的节点来黏贴这两个信息然后链接,显示已连接成功
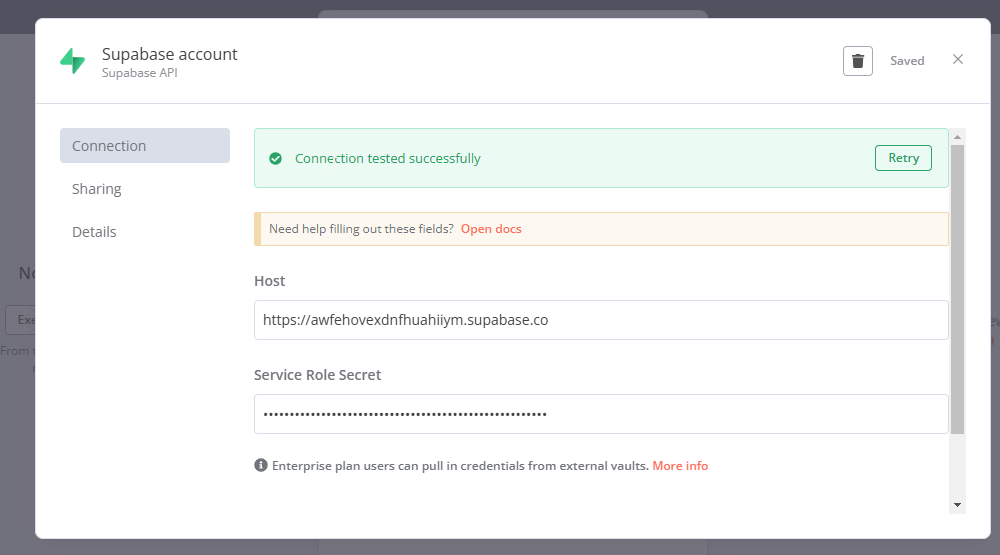
OK,连接成功后,如果我点击这个列表并选择,会发现它是空白的,因为我们没有需要添加的表格。
回到项目,我们看表格编辑器这里,可以看到没有任何表格。
(2)创建表格
我们在n8n的supabase节点这里,点击文档,进到节点说明的页面

然后点击quickstart

复制这里的SQL代码。这里你不需要修改任何地方 (当然,如果您使用OpenAI嵌入,这非常重要。我将向他们展示一下当您添加嵌入模型时这意味着什么。因此,如果您要添加不同的嵌入模型,假设您使用的是羊驼或其他东西,那么请确保更改它。)

ok,复制后,我们黏贴到supabase项目内的SQL editor里,然后点击运行,它就会显示成功。

然后我们看到,已经自动创建了文档存储和搜索。好的,现在回到我们的表格编辑器,你可以看到有一个叫做文档的表格,它是用这一列、内容、元数据和嵌入创建的。好的,所以你要保持一切不变。不要碰任何东西。回到你的n8n。现在如果你点击这个列表的加载,就可以看到表格的选项了。


然后我们在n8n选择文档即可。
另一件事是我们需要在这里添加一个查询,单击选项并将查询名称保留为匹配文档。按默认的保持原样即可。

在supabase里,我们在table里看到也生成了一个document的文件

4、AI模型
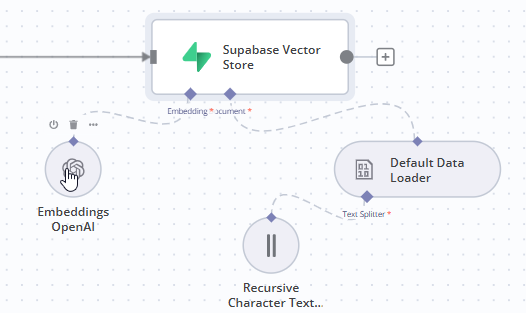
好了,supabase配置好后,我们需要在这里嵌入模型。这里嵌入模型的意义在于,这个模型会将您上传的数据转换为数值表示。这样它就可以在你查询时轻松地搜索它。
在这里我们选择open AI模型即可。这里有三种型号可用。我们选择small即可。
这里说明一下,首先你要有open AI的API权限,然后在open AI去创建一个凭证,在n8n进行连接才可以使用。
5、document loader
现在我们需要添加一个文档加载器,因为我们需要能够通过将Google Drive中的文档拆分为块来将其加载到这个矢量数据库中。所以要获取默认的数据加载器。
所以在这里,我们将选择数据类型为二进制,因为我们希望能够将任何类型的文件添加到这个向量数据,向量数据库中。您可以保持一切不变,因为此数据格式将同时自动检测。这样,无论我们上传什么文档,它都能够检测到并将其添加到向量存储中。


6、text splitters
我们需要通过文本拆分器将此文档拆分为块。这里要使用递归字符文本拆分器。因此,就块大小而言,根据您的文档有多大,可以尝试不同的块大小。由于我的是一个小文档,我将保留1,000的块大小,然后块重叠。所以这就是当它将您的文档分成几个块以便将其处理到这个向量存储中时的位置。然后您要确保添加150或200个字符的块重叠。这样它就不会错过里面的任何数据。


好,完美,然后我们点击测试,就可以看到我们的文档被分成了几个块,并被转换成了向量。
然后它也被添加到了对应的表格中。

这部分就相当于已经完成了。现在我们要继续在这里添加一个向量存储检索器,以便我们可以与此文档进行交互。要做到这一点,我们要继续利用问答链。
二、建立问答机器人
我们需要先添加一个问答链。
将利用一个大型语言模型来与我们可以添加到其中的检索器进行交互。

因为这是一个问答链,意味着它将依赖于某种形式的逻辑。因此,它将依赖于我们可以附加的大型语言模型。因此,您需要确保在此处附加一个大型语言模型。

1、AI模型
首先我们要添加一个AI模型,我们依旧选择open AI。这里选择GPT4 mini就好

2、Vector Store retriever
另外我们需要添加一个retriever,这里就是我们需要添加向量存储检索器的地方。添加Vector Store retriever的节点。无需配置其他内容

3、Supabase Vector Store
接着我们要添加我们保存数据的向量存储。选择Supabase Vector Store的节点,然后做同样的配置


4、AI模型
最后,我们在supabase这里嵌入一个AI模型。同样的配置,这样我们就可以从那里获取我们的信息。

这就是一个问答链了,我们能够通过聊天消息与我们将文件添加到数据中的这个向量存储进行交互。
好的,接着我们试试与此进行互动
我们点击底下的“chat”,问一个与我们上传的文件相关的问题,然后它就能够从该向量存储中提取该数据来回复我们。
在日志中我们可以看到,它从问答链延伸到矢量商店检索器,进入Supabase Vector Store,使用嵌入,然后使用OpenAI聊天模型来回复我们。
完美。

好的,这就是我们如何用supabase和n8n建立一个RAG以及问答机器人的步骤。
无需任何代码,非常的方便。

Embeddings OpenAI节点报错,model下拉为空,手动输入text-embedding-ada-002/003显示不支持,怎么办呢
Embeddings OpenAI节点报错,model下拉为空,手动输入text-embedding-ada-002/003显示不支持,怎么办呢
Embeddings OpenAI节点报错,model下拉为空,手动输入text-embedding-ada-002/003显示不支持,怎么办呢