
做内容和运营的朋友们大概率会有过这种体验:想盯某个关键词在抖音上的表现,比如想看最近一天有哪些高赞视频,就只能每天打开抖音,搜关键词,筛选条件里,排序依据「最多点赞」,发布时间选择「一天内」,一条条看点赞数,然后把超过 1 万的手工记下来。
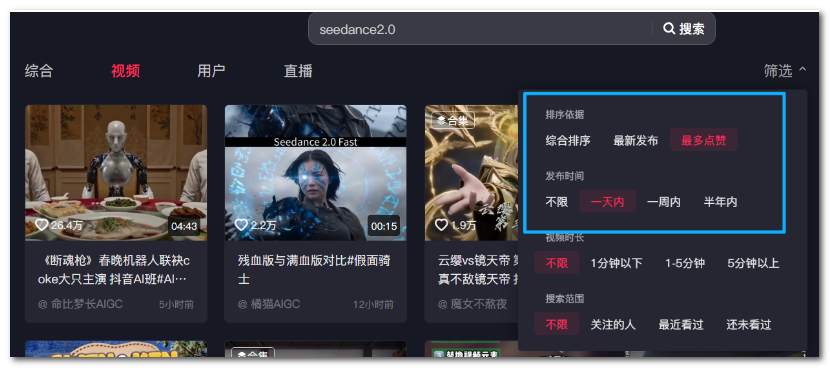
搞几天就发现:每天手动搜、手动筛,太耗时间了,而且容易忘、容易断。
我们经常说,如果你的一个工作只要重复过三次,就可以用自动化来落地提效。
所以,这个工作,能不能让流程每天自动帮我搜一遍,然后把结果存到飞书多维表格里,我只要早上打开表格看一眼、按点赞数排个序筛一筛就行?当然可以。
我用 n8n + TikHub 的抖音搜索接口搭了这个流程:每天固定时间(比如晚上 23:30)跑一次,按我设定的关键词拉「最近 1 天、按点赞排序」的搜索结果,分页拉全后整理成表格字段,全部同步到多维表格。工作流里不做点赞阈值过滤,我在表里用筛选或视图自己筛 1 万以上的数据,这样既省掉每天重复操作,又保留自己判断的灵活性。
不过当我试了几次后,虽然流程正常跑,但是搜出来的结果,会有一点差异,如果想实现抖音关键词搜索自动化的朋友们,今天这篇,就聊聊这个工作流如何搭建,以及里面存在的问题和建议的方式。
一、需要准备些什么工作
搭建n8n流程之前,你需要准备的内容:
1.n8n:开源自动化工作流工具,用节点把「触发 → 请求 API → 处理数据 → 写库」串起来。
- 云版去 n8n.io 注册即可;
- 想免费用就自部署(如 zeabur 一键部署)。
2.TikHub API:tikhub.io 注册、充值、拿 Token,在 n8n 的 HTTP 请求里用 Header:Authorization: Bearer 你的Token。
3.飞书应用 + 多维表格:open.feishu.cn 创建企业自建应用,开好多维表格权限,拿到 App ID、App Secret;新建多维表格后,从浏览器地址栏里摘出 App Token 和 Table ID,写接口时要用。
4.多维表格字段:建一张表,字段和后面写入的对应即可,如:视频 id、视频描述文字、发布时间、作者昵称、粉丝数、点赞数、评论数、分享数、播放数、视频链接、关键词(类型按文本/数字/URL 设好)。
二、整体n8n流程的思路 + 各节点说明
我们先讲如何用n8n流程来实现抖音关键词搜索。
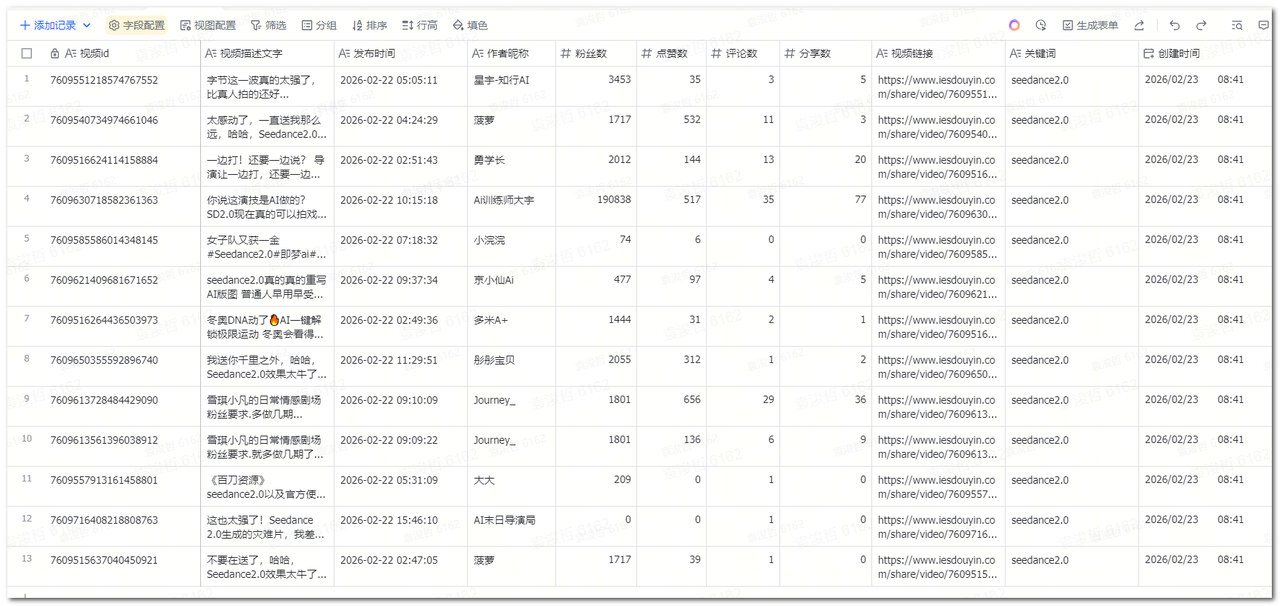
流程的效果大概是这样:工作流会自动完成这几件事:定时启动(如每天 23:30)→ 按你配置的关键词调用 TikHub 抖音视频搜索接口 → 只抓最近 1 天、按点赞排序 → 分页拉全(用接口的 cursor / has_more 循环直到没有下一页)→ 整理字段并去重(抽出视频 id、描述、发布时间、作者、粉丝数、点赞/评论/分享/播放、链接、关键词)→ 写入飞书多维表格,每条视频一行。结果:你打开飞书多维表格,会看到一张按关键词、按天沉淀的抖音搜索结果表。你在表里自己筛「点赞数 ≥ 1 万」、排序、做视图或简单分析就行。
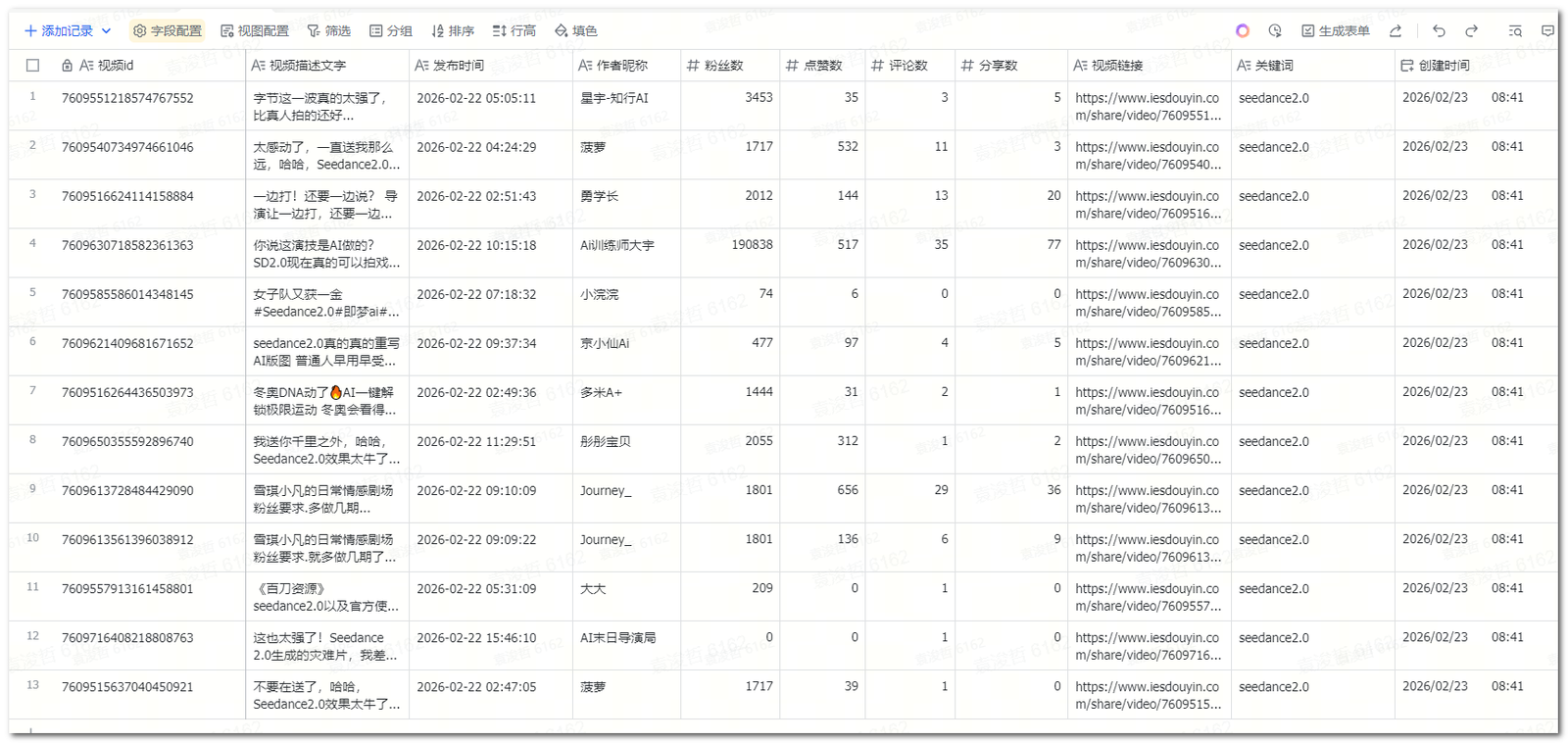
(同步到多维表格的数据)
实现思路是这样:定时触发 → 初始化关键词和分页参数 → 调抖音搜索 API → 分页汇总(合并当前页、判断是否还有下一页)→ 若还有则更新 cursor 再请求,若没有则整理字段 → 展开成逐条 → 取飞书 Token → 逐条写入多维表格。
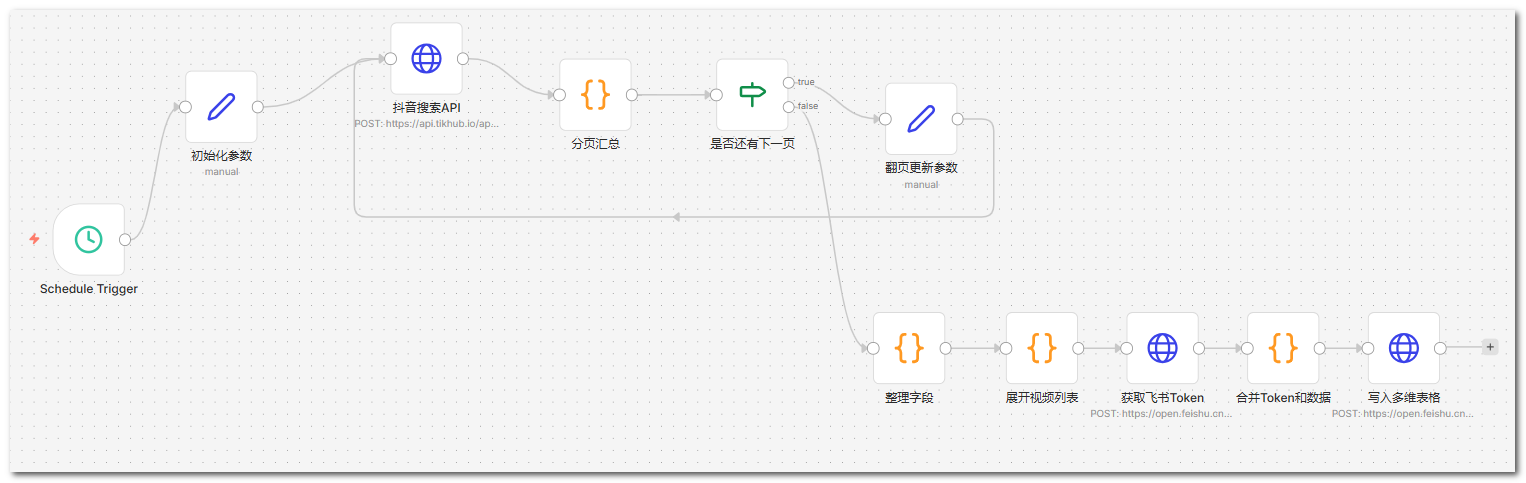
(n8n工作流)
接下来说说每个节点的目的和配置要点都是什么。
1.Schedule Trigger(定时触发)
流程的开始节点,启动后,流程每天自动跑,我们就不用手动点了。比如设置触发时间是每天的23:30,这样当天发布的视频已经沉淀一段时间,获取的数据就会更全面一些。
2.初始化参数(Set)
把关键词和分页相关参数(cursor=0、search_id、backtrace、allRawVideos=[])放在一起,后面「抖音搜索API」和翻页时都从这里或从分页结果里取数,如果我们要改搜索的关键词,就改这里就行。
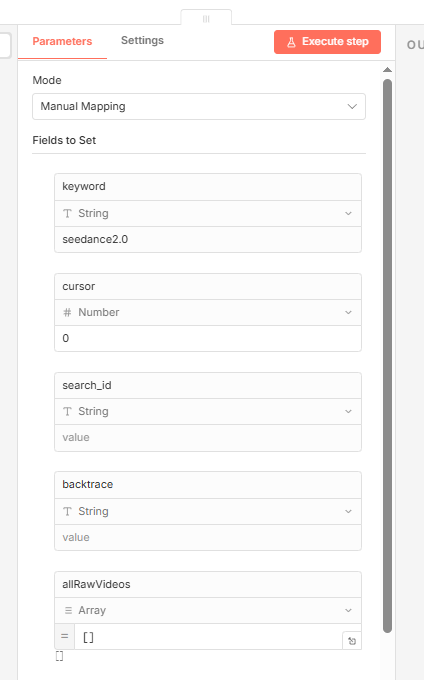
3.抖音搜索API(HTTP Request)
这里就是调用tikhub的抖音关键词搜索接口,来获取搜索后的数据
在body里我们按接口文档配置好需要的参数值
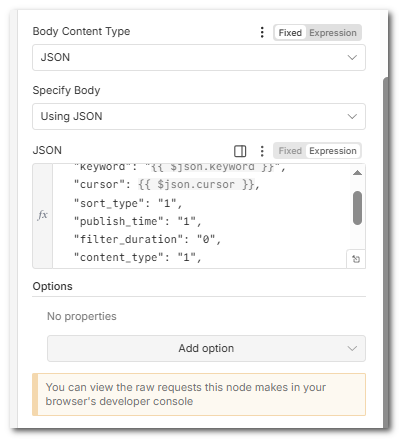
说明:keyword就是搜索的关键词,sort_type=1 按最多点赞排序,publish_time=1 只取最近一天。首次请求时 cursor=0、search_id 和 backtrace 为空;翻页时由「分页汇总」从接口返回里取出并交给「翻页更新参数」,再回到本节点。
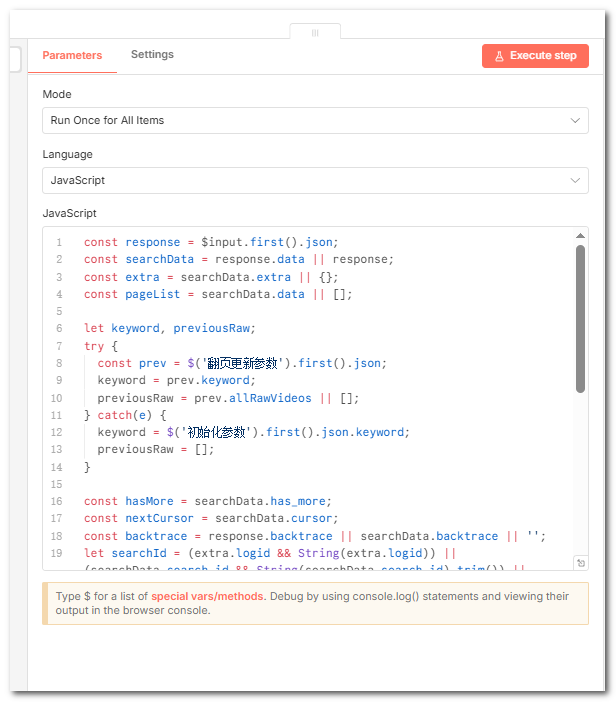
4.分页汇总(Code)
因为接口一页只返回有限条,要获取更多的数据,就涉及到分页。
所以这个节点,我们用js把所有页拼在一起,这才是「该关键词最近 1 天」的完整列表。这个节点从当前页响应里取出视频列表、和前面几页合并,再取出 has_more、cursor、search_id、backtrace,给后面判断「是否继续翻页」用。
5.是否还有下一页(IF)
因为有时候数据可能只有一页,有时可能不止,这个是根据搜索结果来判断的,是否有多页,是根据接口里的一个has_more字段决定的。如果是1,就需要继续翻页(走「翻页更新参数」再请求一次 API),如果为0,就直接结束拉取,进入整理和写表。
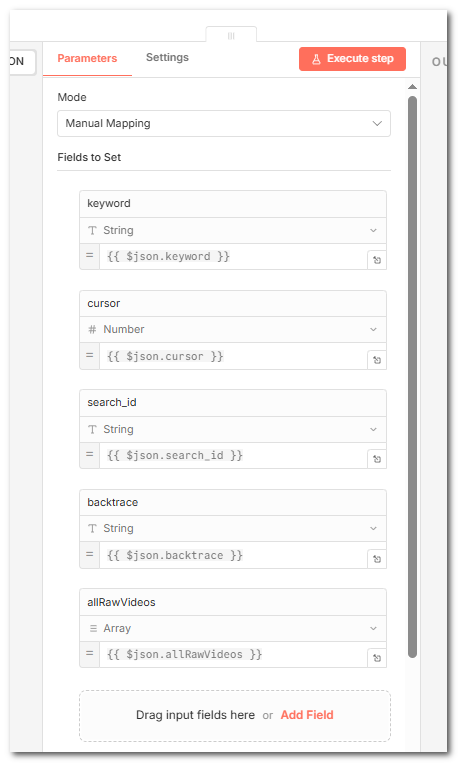
6.翻页更新参数(Set)
当还有下一页时,把这一轮分页汇总得到的 keyword、cursor、search_id、backtrace、allRawVideos 写回去,连回「抖音搜索API」,形成循环,下一轮请求就会带上新的 cursor。
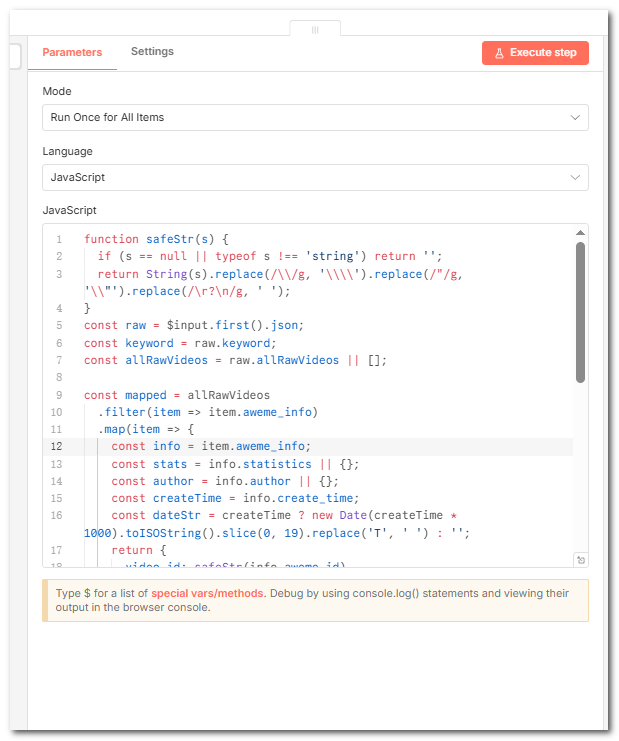
7.整理字段(Code)
因为接口返回的数据是一个非常复杂的嵌套结构(aweme_info、statistics、author 等),我们就需要根据它返回的数据的格式,来进行数据的加工,核心目的就是把它加工成多维表格需要的字段。
并且这里还有两个逻辑要注意
①字符串转义:避免描述、链接里的换行、双引号导致写入飞书多维表格时报 JSON格式的错误)
②按 share_url 去重:同一次运行里同一链接只保留一条,避免每次搜索把相同的数据重复写入到多维表格里。
8.展开视频列表(Code)
因为「整理字段」节点输出是一条 item,里面一个数组 allVideos。写飞书多维表格时要每条视频发一条请求,所以先把数组展开成「每个元素一条 item」。
这个节点,其实也是起到一个数据加工和格式转换的作用。
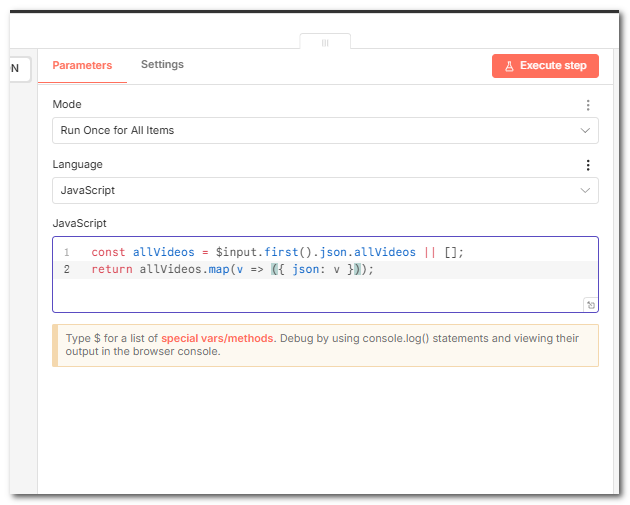
9.获取飞书 Token(HTTP Request)
按飞书接口调用的规范,需要先拿 App ID + App Secret 换 tenant_access_token,再调多维表格接口。这里每次跑都先换一次 Token。
10.合并 Token 和数据(Code)
把 Token 塞进每一条视频 item 里,这样后面「写入多维表格」时每条都自带 token,Header 里用 Authorization: Bearer {{ $json.feishu_token }} 即可。
11.写入多维表格(HTTP Request)
调用飞书多维表格批量新增记录的接口。把每条视频写成多维表格里的一条记录,fields 和多维表格列名一一对应。这一步,我们把所有拉到的视频数据都写进多维表格里,然后我们在表里用筛选或视图自己筛选数据即可,这样更灵活
流程配置完成并运行后,抖音搜索后的数据就自动同步到多维表格里了 。
三、存在的问题
其实细心的朋友应该已经注意到一个问题:拿同一个关键词,在不同的地方搜索,结果都会不一样。
比如,我同时间用同样的搜索条件在四个地方对比了一下:
- 抖音网页版搜同一关键词(如seedance2.0)
- 抖音 App 搜同一关键词(如seedance2.0)
- n8n + TikHub 接口拉到的列表(关键词搜seedance2.0)
- 同第三方数据平台(如灰豚)搜同一关键词
结论是:四份结果并不一致。 有的视频只在接口里有、App 里没看到;有的在灰豚里排在前面,在接口结果里却不在前几页。一开始我怀疑是接口有 bug 或其他什么原因,后来查了查才发现,不是谁对谁错,而是抖音的搜索本身就不是「一个唯一标准答案」。所以导致不同渠道,不同账号,搜索出来的结果都不同。
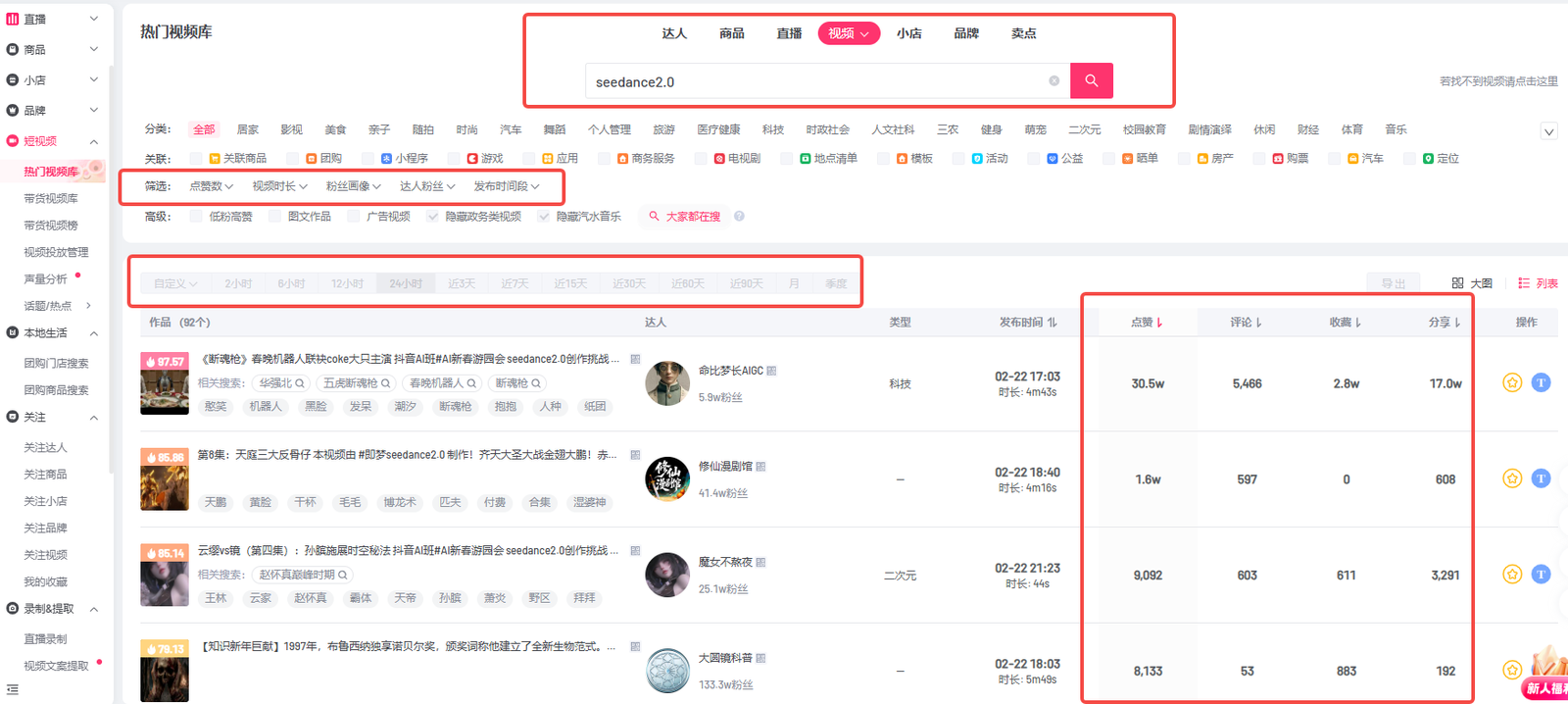
(比如这个是在灰豚搜到的)
四、抖音搜索机制大致是怎样的?
我查了查资料,大概理解了为什么各端结果会不一样
1. 搜索 ≠ 纯关键词匹配
抖音是推荐驱动的,搜索也是「推荐式搜索」:不是数据库里做一次关键词匹配就完事,而是会做语义理解、主题聚类、用户兴趣、内容质量、互动权重等一起算。所以搜索结果是「系统认为你可能想看什么」,而不是「全网所有相关内容」的完整列表。
2. App 搜索是高度个性化的
在 App 里,同一关键词,不同账号、不同设备、不同地区、不同历史行为,结果都可能不同。会参考你的观看时长、互动偏好、关注领域、是否商业号等。所以:你在接口里搜到的某条视频,在自己 App 里搜不到,很正常。接口侧一般没有「你」这个用户,走的是另一套排序或通用策略。
3. 网页端和 App 端策略也不一样
通常理解是:App 更偏个性化推荐,网页端相对偏展示、弱个性化。所以网页和 App 结果本身就不必一致;接口又可能是另一套(例如偏某一种排序或采样),三者不一致是预期内的。
4. 第三方平台(灰豚、蝉妈妈等)为什么又不同?
这类平台往往有自己的爬虫、采样、缓存、去重和过滤逻辑,不一定是官方公开接口,很多是「模拟请求 + 采样 + 历史库补全」。当然也可能这种第三方平台和抖音有合作。所以它们给出的结果和你在 App 里看到的,也是不一样的。
5. 接口本身的限制
以 TikHub 这类接口为例:只能按某一种或几种排序拉、只能拉前 N 页或有限深度、有频率限流,返回的是「某次搜索结果页」的数据,不是全量。而且抖音本身也没有公开「完整搜索 API」,所以不存在「用接口就能拿到和 App 一模一样的全量结果」这回事。
6. 排序大概会受哪些因素影响?
虽然算法不公开,但实操里常见因素会包括:关键词匹配度、发布时间、点赞/评论/转发、完播、账号权重、近期增长、是否投流、用户匹配度等等。抖音搜索并不是「按点赞数排序」这一维,而是综合权重。所以我们用「点赞 > 1 万」在结果里筛,只是一个二次过滤,而不是复现平台本身的排序。
7. 没有单一方式能拿到「全量」
想尽量多覆盖,一般只能尝试组合策略了,比如多关键词、翻页拉满、时间分段、多账号/多端各搜一份再合并、搜索+话题页一起抓….当然,这种方式就太复杂了,先不说耗费的接口费用,这些复杂的搭建逻辑就很难一个人搞定,而且投入产出比极低。
五、用法建议:什么时候用接口,什么时候用专业数据平台
上面的问题说完后,你可能会问那怎么办?
如果说你数据的稳定性、口径、可复现性要求比较高,真正是要做数据复盘、竞品跟踪的,我建议还是用灰豚等专业的第三方数据平台。毕竟要维护成「更稳定、更接近业务口径的榜单/历史沉淀/跨账号对比」,成本会比较高,不是一个人简单能搞定的,而灰豚这类平台在数据清洗、去重、指标定义、更新频率上通常更成熟更专业,虽然数据会有一定的延迟,但完全是够用了,毕竟站在巨人的肩膀上,把精力可以用在其他的地方上。
而且账号费用也不贵,直接去某鱼就可以搞定。
那我们搭建的这个n8n流程呢?是不是就没用了,也不是,其实可以作为辅助,每天定期跑和拉数据,做为补充。以灰豚等专业数据为主。两边一起使用。
写在最后
一开始搭这个工作流的时候没想这么多,真正运行的时候才发现抖音搜索的复杂性,所以对于我们产品经理和IT/AI博主来说,真不是把东西搭完就完事了,真正放在实际业务场景中使用,才会发现里面各种问题,而真正有价值的地方,也是在于如何解决这些潜在问题,如何有更好的方案来满足各种业务场景,而不是简单的想当然,共勉。
最后是广告时间
如果你也对多维表格/n8n自动化工作流的知识和教程感兴趣,欢迎订阅我的小报童专栏。
专栏会持续更新详细的多维表格/n8n的配置方法、详细教程,以及实际应用场景/案例。
目前累计已更新84篇,总计28.4万字。 限时价格99元(永久)。
课程目录:
小报童订阅入口:
或用手机微信扫描下方二维码

**gl pro**
GL Pro is a natural dietary supplement formulated to help maintain steady, healthy blood sugar levels while easing persistent sugar cravings.
**nervecalm**
NerveCalm is a high-quality nutritional supplement crafted to promote nerve wellness, ease chronic discomfort, and boost everyday vitality.
**mounja boost**
MounjaBoost is a next-generation, plant-based supplement created to support metabolic activity, encourage natural fat utilization